【天风海外】TPU能取代GPU吗?谷歌云计算MLaaS脱颖而出的差异化

作者:天风海外
TPU目前未能取代GPU,依托云计算拓宽MLaaS需求
TPU目前未能取代GPU,只是在某些特定算法上做针对性优化。谷歌这次将TPU开放给客户是为了提供云计算服务的差异化,提升谷歌云的机器学习即服务(MLaaS)易用性。谷歌目前没有以硬件产品方式出售TPU的计划,而是依靠TPU浮点运算精度的提高及针对TensorFlow的深度优化,以云计算服务形式销售共享。与我们此前强调的一致,我们认为Google通过Cloud TPU+TensorFlow的软硬结合,以及此后TPU Pod的加持,可进一步激活中小企业以及科研单位的云计算需求,另辟AWS、Azure之外蹊径。
谷歌云Q4单季收入跨越10亿美元门槛,但相对于AWS 51亿,微软智能云78亿的体量尚不能及;AWS龙头尚稳份额增加0.5%,微软份额增加3%为最多;谷歌份额增加1%。当前包括亚马逊AWS、微软Azure都提供了机器学习基本工具,而通过TensorFlow API+TPU,Google提供包括图像识别ResNet-50、机器翻译Transformer和物体识别RetinaNet在内的主流模型训练开发功能,日后还会提供其他服务。此外Google针对TPU的使用进行功耗优化,进一步降低数据中心的运营成本。我们认为,云计算巨头为了提高在使用服务器芯片时的议价能力,未来会消防Google寻求自主芯片开发的方案,但主要针对特定需求进行定制开发。
ASIC专用性最好实证,谷歌TPU以时间换吞吐量
AI立夏已至,以ASIC为底芯片的包括谷歌的TPU、寒武纪的MLU等,也如雨后春笋。但我们此前强调包括TPU在内的ASIC仍然面临通用性较弱,以及开发成本高企等局限。TPU虽理论上支持所有深度学习开发框架,但目前只针对TensorFlow做了深度优化。另外ASIC芯片开发周期长和成本非常高,在开发调试过程中复杂的设计花费有时甚至会花数亿美元,因此需要谷歌这样的计算需求部署量才能将成本分摊到大量使用中。同时ASIC开发周期长,也可能会出现硬件开发无法匹配软件更新换代而失效的情况。
TPU是针对自身产品的人工智能负载打造的张量处理单元TPU。第一代主要应用于在下游推理端TPU。本质上沿用了脉动阵列机架构(systolic array computers),让推理阶段以时间换吞吐量。第二代TPU除了在推理端应用,还可以进行深度学习上游训练环节。
AI芯片蓝海仍是GPU引领主流,ASIC割据一地,看好未来各领风骚
我们仍然强调:在人工智能浪潮中,芯片市场蛋糕越做越大,足以让拥有不同功能和定位的芯片和平共存,百花齐放。后摩尔定律时代,AI芯片间不是零和博弈。我们认为在3-5年内深度学习对GPU的需求是当仁不让的市场主流。在深度学习上游训练端(主要用在云计算数据中心里),GPU作为第一选择,英伟达表示Hyperscale巨头作为第一波客户在训练端的复购高渗透率正在向推理端延伸,针对数据中心推理的P4处理器开始出货,第二波客户则是其他云计算大公司开始放量,第三波客户则是基于云计算的互联网企业海量的数据和AI应用计算需求。
而下游推理端更接近终端应用,需求更加细分,我们认为除了GPU为主流芯片之外,包括CPU/FPGA/ASIC等也会在这个领域发挥各自的优势特点。FPGA适用于开发周期较短的IoT产品、传感器数据预处理工作以及小型开发试错升级迭代阶段等。以TPU为代表的ASIC定制化芯片,包括英特尔的Nervana Engine、Wave Computing的数据流处理单元、以及英伟达的DLA等,针对特定算法深度优化和加速,将在确定性执行模型(deterministic execution model)的应用需求中发挥作用。我们认为深度学习ASIC芯片将依靠特定优化和效能优势,未来在细分市场领域发挥所长。
风险提示:芯片开发周期过长,市场需求不达预期等。
1、谷歌TPU:以时间换吞吐量,软硬兼施,冲入云端
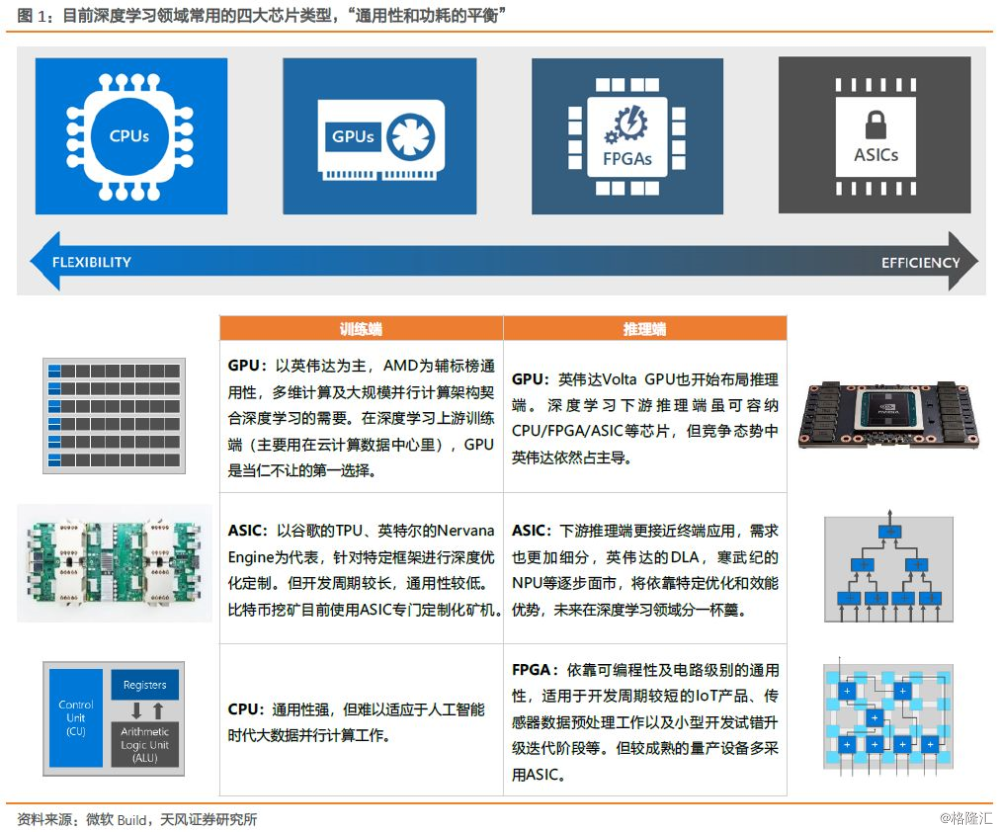
AI芯片市场蛋糕越做越大,足以让拥有不同功能和定位的芯片和平共存,百家争鸣非零和博弈。“通用性和功耗的平衡”——在深度学习上游训练端(主要用在云计算数据中心里),GPU是当仁不让的第一选择,ASIC包括谷歌TPU、寒武纪MLU等也如雨后春笋。而下游推理端更接近终端应用,需求更加细分,GPU主流芯片之外,包括CPU/FPGA/ASIC也会在这个领域发挥各自的优势特点。
但我们需要强调,包括TPU在内的ASIC仍然面临通用性较弱,以及开发成本高企等局限。TPU虽然理论上支持所有深度学习开发框架,但目前只针对TensorFlow进行了深度优化。另外ASIC芯片开发周期长和成本非常高,在开发调试过程中复杂的设计花费有时甚至会超过亿美元,因此需要谷歌这样的计算需求部署量才能将成本分摊到大量使用中。同时ASIC开发周期长,也可能会出现硬件开发无法匹配软件更新换代而失效的情况。
ASIC(Application Specific Integrated Circuit,专用集成电路):细分市场需求确定后,以TPU为代表的ASIC定制化芯片(或者说针对特定算法深度优化和加速的DSA, Domain-Specific-Architecture),在确定性执行模型(deterministic execution model)的应用需求中发挥作用。我们认为深度学习ASIC包括英特尔的Nervana Engine、Wave Computing的数据流处理单元、英伟达的DLA、寒武纪的NPU等逐步面市,将依靠特定优化和效能优势,未来在深度学习领域分一杯羹。
神经网络的两个主要阶段是训练(Training和Learning)和推理(Inference和Prediction)。当前几乎所有的训练阶段都是基于浮点运算的,需要进行大规模并行张量或多维向量计算,GPU依靠优秀的通用型和并行计算优势成为广为使用的芯片。
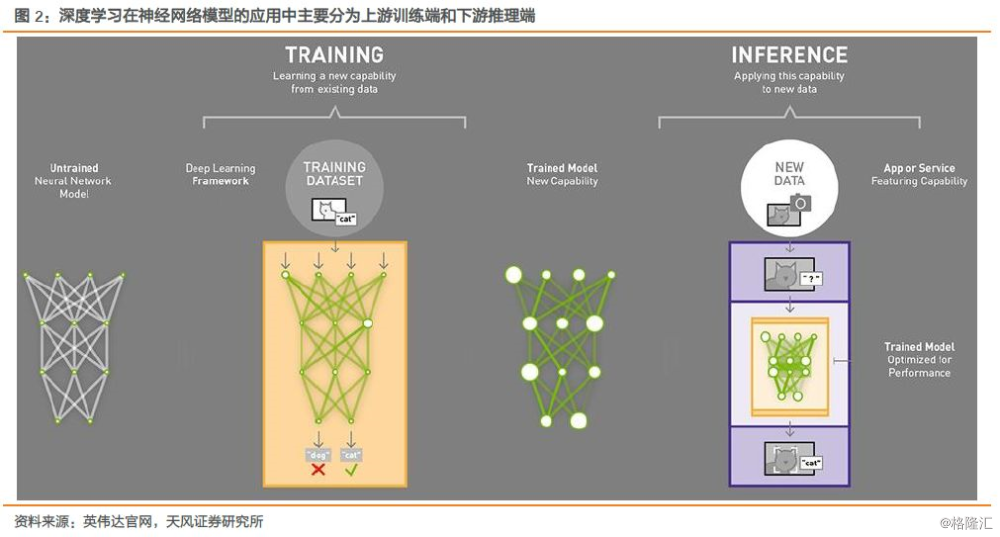
在推理阶段,由于更接近终端应用需求,更关注响应时间而不是吞吐率。由于CPU和GPU结构设计更注重平均吞吐量(throughout)的time-varying优化方式,而非确保延迟性能。谷歌设计了一款为人工智能运算定制的硬件设备,张量处理单元(TensorProcessing Unit, TPU)芯片,并在2016年5月的I/O大会上正式展示。

第一代TPU的确定性执行模型(deterministicexecution model)针对特定推理应用工作,更好的匹配了谷歌神经网络在推理应用99%的响应时间需求。第一代TPU是在一颗ASIC芯片上建立的专门为机器学习和TensorFlow量身打造的集成芯片。该芯片从2015年开始就已经在谷歌云平台数据中心使用,谷歌表示TPU能让机器学习每瓦特性能提高一个数量级,相当于摩尔定律中芯片效能往前推进了七年或者三代。
谷歌表示,这款芯片目前不会开放给其他公司使用,而是专门为TensorFlow所准备。TPU的主要特点是:
1、从硬件层面适配TensorFlow深度学习系统,是一款定制的ASIC芯片,谷歌将TPU插放入其数据中心机柜的硬盘驱动器插槽里来使用;
2、数据的本地化,减少了从存储器中读取指令与数据耗费的大量时间;
3、芯片针对机器学习专门优化,尤其对低运算精度的容忍度较高,这就使得每次运算所动用的晶体管数量更少,在同时间内通过芯片完成的运算操作也会更多。研究人员就可以使用更为强大的机器学习模型来完成快速计算。

自2016年以来,TPU运用在人工智能搜索算法RankBrain、搜索结果相关性的提高、街景Street View地图导航准确度提高等方面。在I/O大会上,皮查伊顺带提到了16年3月份行的举世瞩目人机大战里,在最终以4:1击败围棋世界冠军李世石的AlphaGo身上,谷歌也使用了TPU芯片。
谷歌把:
1、2015年击败初代击败樊麾的版本命名为AlphaGo Fan,这个版本的AlphaGo运行于谷歌云,分布式机器使用了1202个CPU和176个GPU。
2、2016年击败李世石的版本AlphaGo Lee则同样运行于云端,但处理芯片已经简化为48个第一代TPU。
3、2017年击败柯洁的Master以及最新版本Zero则通过单机运行,只在一个物理服务器上部署了4个第一代TPU。(AlphaGo的背后算法详解,可参见我们此前的深度报告《谷歌人工智能:从HAL的太空漫游到AlphaGo,AI的春天来了》)

1.1. 谷歌TPU软硬兼施,加速云端AI帝国
AI芯片领域数据中心市场空间巨大,我们看到市场主流GPU之外,谷歌破局者之态依靠TPU 2.0的浮点运算升级自下而上进入云计算服务。谷歌当下不直接销售硬件,但将TPU部署在云计算中以云服务形式进行销售共享,在为数据中心加速市场带来全新的需求体验的同时,可进一步激活中小企业的云计算需求市场,另辟AWS、Azure之外蹊径。我们长期看好谷歌基于公司AI First战略规划打造AI开发软硬件一体化开发帝国。
不过TPU虽然理论上支持所有深度学习开发框架,但目前只针对TensorFlow进行了深度优化。而英伟达GPU支持包括TensorFlow、Caffe等在内所有主流AI框架。因此谷歌还在云计算平台上提供基于英伟达Tesla V100 GPU加速的云服务。在开发生态方面,TensorFlow团队公布了TensorFlow Research Cloud云开发平台,向研究人员提供一个具有1000个云TPU的服务器集群,用来服务各种计算密集的研究项目。

1.2. 第一代TPU:脉动阵列“获新生”,以时间换吞吐量
第一代TPU面向的推理阶段,由于更接近终端应用需求,更关注响应时间而不是吞吐率。相对于CPU和GPU结构设计更注重平均吞吐量(throughout)的time-varying优化方式,而非确保延迟性能。第一代TPU的确定性执行模型(deterministicexecution model)针对特定推理应用工作,更好的匹配了谷歌神经网络在推理应用上99%的响应时间需求。由于TPU没有任何存储程序,仅执行从主机发送的指令,这些功能的精简让TPU有效减小芯片面积并降低功耗。
谷歌在2017年4月的体系结构顶会ISCA 2017上面,发布了一篇介绍TPU相关技术以及与其它硬件比较的论文,并被评为最佳论文。我们通过论文得以看到第一代TPU的设计思路以及性能比较。
第一代TPU从2015年开始就被使用在谷歌云计算数据中心的机器学习应用中,面向的是推理阶段。首先看性能比较(鉴于2016年以前大部分机器学习公司主要使用CPU进行推理,谷歌在论文中TPU的比较对象产品为英特尔服务器级Haswell CPU和英伟达Tesla K80 GPU),谷歌表示:
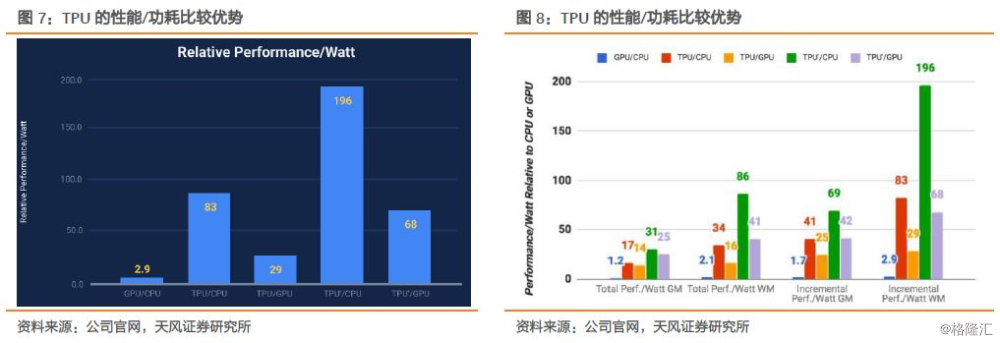
1、 针对自身产品的人工智能负载,推理阶段,TPU处理速度比CPU和GPU快15-30倍;
2、 TPU的功耗效率(TOPS/Watt,万亿次运算/瓦特)也较传统芯片提升了30-80倍;
3、 基于TPU和TensorFlow框架的神经网络应用代码仅需100-1500行。
基于在成本-能耗-性能(cost-energy-performance)上的提升目标,TPU的设计核心是一个65,536(256x256)个8位MAC组成的矩阵乘法单元(MAC matrix multiply unit),可提供峰值达到92 TOPS的运算性能和一个高达28 MiB的软件管理片上内存。TPU的主要设计者Norman Jouppi表示,谷歌硬件工程团队最开始考虑过FPGA的方案,实现廉价、高效和高性能的推理解决方案。但是FPGA的可编程性带来的是与ASIC相比在性能和每瓦特性能的巨大差异。
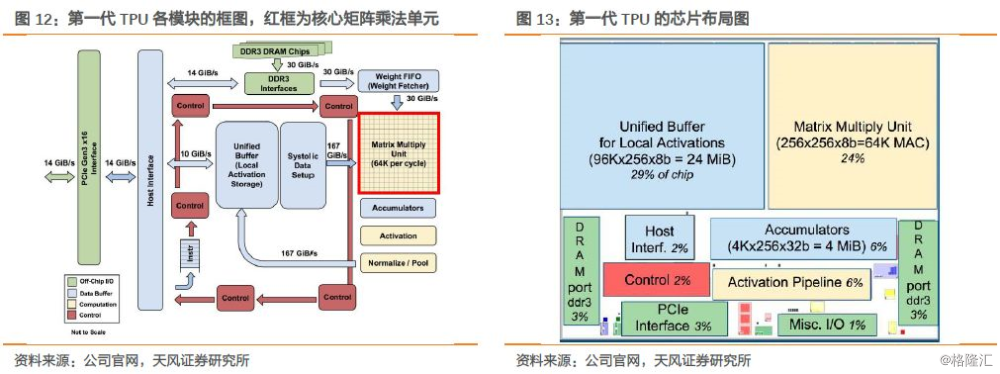
从上图我们看到,TPU的核心计算部分是右上方的黄色矩阵乘法单元(MatrixMultiply unit),输入部分是蓝色的加权FIFO和一致缓冲区(UnifiedBuffer,输出部分是蓝色的累加器(Accumulators)。在芯片布局图中我们看到,蓝色的缓存的面积占37%,黄色的计算部分占30%,红色的控制区域只占2%,一般CPU、GPU的控制部分会更大而且难以设计。
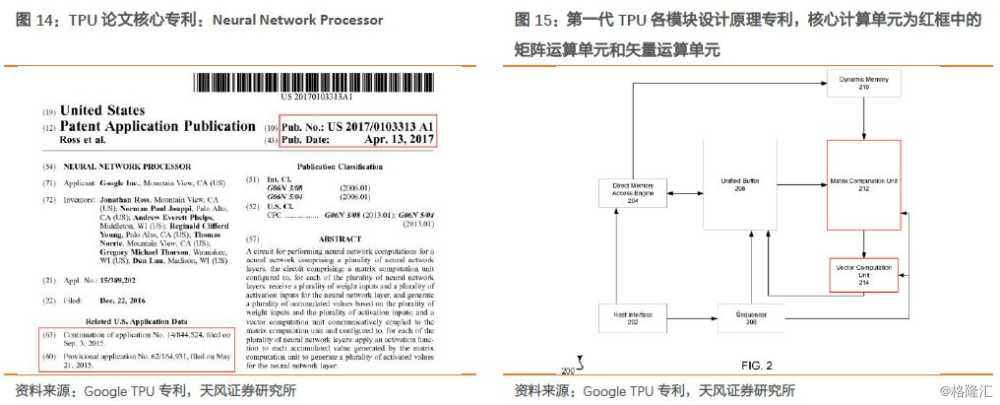
我们深挖谷歌TPU论文,在参考文献中提及了谷歌申请的专利,核心的专利NeuralNetwork Processor作为总构架在2015年就已提交,并在2016年公开(后续专利在2017年4月公开,专利号:US 2017/0103313,即下图12所示),同时还包括了几个后续专利:如何在该构架上进行卷积运算、矢量处理单元的实现、权重的处理、数据旋转方法以及Batch处理等。
专利摘要概述:一种可以在多网络层神经网络中执行神经网络计算的电路,包括一个矩阵运算单元(matrixcomputation unit):对多个神经网络层中的每一层,可以被配置为接收多个weights输入和多个activation输入,并对应生成多个累积值;以及矢量运算单元(vector computation unit),其通信耦合到所述矩阵运算单元。
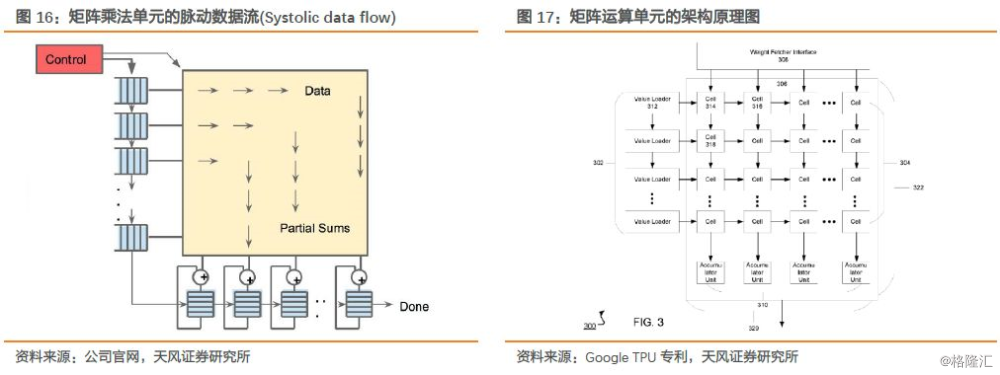
TPU的设计思路比GPU更接近一个浮点运算单元,是一个直接连接到服务器主板的简单矩阵乘法协处理器。TPU上的DRAM是作为一个独立的并行单元,TPU类似CPU、GPU一样是可编程的,并不针对某一特定神经网络设计的,而能在包括CNN、LSTM和大规模全连接网络(large, fully connected models)上都执行CISC指令。只是在编程性上TPU使用矩阵作为primitive对象,而不是向量或标量。TPU通过两个PCI-E 3.0 x8边缘连接器连接协处理器,总共有16GB/s的双向带宽。
我们看到,TPU的matrix单元就是一个典型的脉动阵列架构(systolic array computers)。weight由上向下流动,activation数据从左向右流动。控制单元实际上就是把指令翻译成控制信号,控制weight和activation如何传入脉动阵列以及如何在脉动阵列中进行处理和流动。由于指令比较简单,相应的控制也是比较简单的。
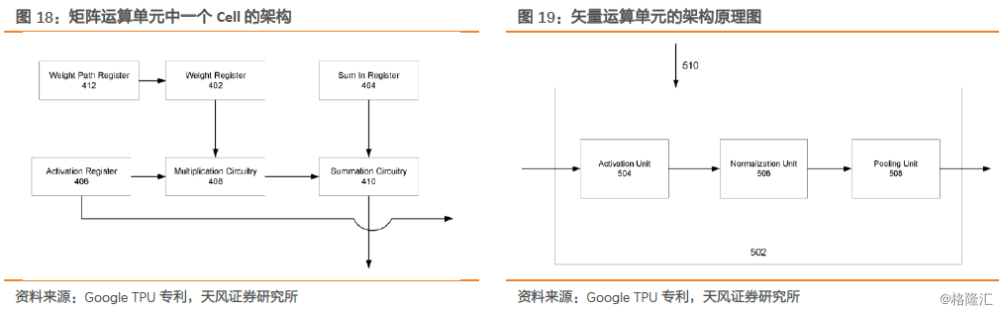
从性能上,脉动阵列架构在大多数CNN卷积操作上效率很好,但在部分其他类型的神经网络操作上,效率不是太高。另外脉动阵列架构在上世纪80年代就已经被提出,Simple and regular design是脉动阵列的一个重要原则,通过简单而规则的硬件架构,提高芯片的设计和实现的能力,从而尽量发挥软件的能力,并平衡运算和I/O的速度。脉动阵列解决了传统计算系统:数据存取速度往往大大低于数据处理速度的问题,通过让一系列在网格中规律布置的处理单元(Processing Elements,PE),进行多次重用输入数据来在消耗较小的带宽的情况下实现较高的运算吞吐率。但是脉动阵列需要带宽的成比例的增加来维持所需的加速倍数,所以可扩展性问题仍待解决。
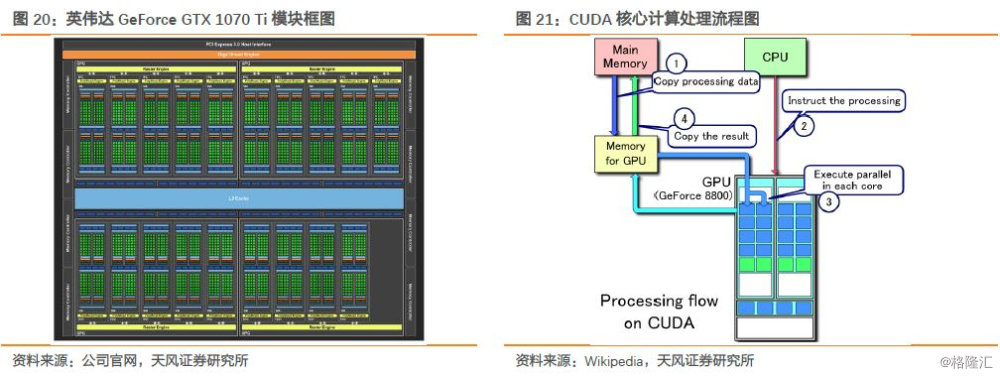
对比GPU的硬件架构,英伟达的游戏显卡GeForce GTX1070 Ti使用的是Pascal架构16纳米制程,主频1,60 7MHz,拥有2,432个CUDA核心和152个纹理单元,2 MB L2 cache,功耗180 W,8GB GDDR5内存。英伟达GPU的核心计算单元CUDA核心专为同时处理多重任务而设计,数千个CUDA核心组成了GPU的大规模并行计算架构。而在计算过程中,主要计算流程为:1)从主机内存将需要处理的数据read到GPU的内存;2)CPU发送数据处理执行给GPU;3)GPU执行并行数据处理;4)将结果从GPU内存write到主机内存。通过编译优化把计算并行化分配到GPU的多个core里面,大大提高了针对一般性通用需求的大规模并发编程模型的计算并行度。
1.3. 第二代TPU:可进行深度学习上游训练计算
第二代TPU,又名Cloud TPU,能够同时应用于高性能计算和浮点计算,峰值性能达到180 TFLOPS/s。与第一代TPU只能应用于推理不同,第二代TPU还可以进行深度学习上游训练环节。随着第二代TPU部署在Google Compute Engine云计算引擎平台上,谷歌将TPU真正带入云端。
谷歌在2017年5月17日举办了年度I/O开发者大会。一场并未有太多亮点的大会上,谷歌CEO皮查伊继续强调公司AI First的传略规划。最为振奋人心的当属第二代TPU——Cloud TPU的发布。

谷歌同时发布了TPU Pod,由64台第二代TPU组成,算力达11.5 petaflops。谷歌表示1/8个TPU Pod在对一个大型机器翻译模型训练的只需要6个小时,训练速度是市面上32块性能最好的GPU的4倍。
谷歌此前强调,第一代TPU是一款推理芯片,并不用作神经网络模型训练阶段,训练学习阶段的工作仍需交由GPU完成。早在16年I/O大会上公布TPU之前,谷歌就已经将TPU应用在各领域任务中,包括:图像搜索、街景、谷歌云视觉API、谷歌翻译、搜索结果优化以及AlphaGo的围棋系统中。
而这次第二代TPU的升级,自下而上的进入深度学习上游,应用在图像和语音识别,机器翻译和机器人等领域,加速对单个大型机器学习模型的训练。第二代TPU在左右两侧各有四个对外接口,左侧还有两个额外接口,未来可能允许TPU芯片直接连接存储器,或者是高速网络,实现更加复杂的运算以及更多的扩展功能。在半精度浮点数(FP16)情况下,第二代TPU的单芯片可以达到45 Teraflops(每秒万亿次的浮点运算),4芯片的设计能达到180 Teraflops。(对比第一代TPU算力:8位整数运算达92 TOPS,16位整数运算达23 TOPS)


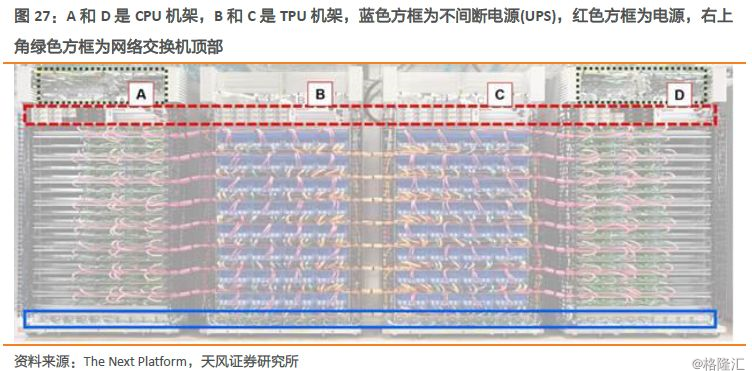
对TPU Pod的结构进行简要分析,四机架的镜像结构包含64个CPU板和64个第二代TPU板,The Next Platform推测CPU板是标配英特尔Xeon双插槽主板,因此整个Pod机柜包括128个CPU芯片和256个TPU芯片。
The Next Platform认为,谷歌使用两条OPA线缆将每块CPU板一一对应连接至TPU板,使得TPU与CPU的使用比例为2:1,这种TPU加速器与处理器之间高度耦合的结构,与典型的深度学习加速结构中GPU加速器4:1或6:1的比例不太一样,更强调了TPU作为协处理器的设计理念——CPU处理器还是需要完成大量的计算工作,只是把矩阵计算的的任务卸载到TPU中完成。
报告来源:天风证券研究所海外团队
报告发布时间:2018年2月13日
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。


