给阿里千问一个“客观估计”——围绕QWen3的大模型横评


导语:Qwen3 旗舰模型已进入全球第一梯队、国内Top 2–3的行列:综合能力略低于Gemini3、GPT-5.1和Kimi K2 Thinking,但与Grok 4.1、Claude Opus 4.1属于同档。
阿里近期发布的千问App引发了外界的关注,其背后的Qwen3大模型与国际和国内几大模型的性能对比,到底水平如何?对用户来说又该如何根据不同的任务来选择不同的大模型?今天给大家做个对比与总结。
01 Qwen3的基本面
阿里在今年推出的第三代大模型Qwen3,是千问App的核心底座。它有几个关键特点:
一、体量和架构
Dense模型:从0.6B一直到32B;
MoE旗舰:Qwen3-235B-A22B(235B 总参数、22B 活跃参数),相当于“参数巨舰+算力省电”。
二、训练规模
训练数据约36万亿token,覆盖119种语言/方言。对数学、代码、STEM推理做了额外强化。提供“Thinking 模式”,类似GPT-o1 / DeepSeek-R1那种显式推理版。
三、应用形态
包括文本对话、写作、代码、多模态(图像/文档/表格),长上下文版本能支持百万级token,对长文档场景很友好。
千问App由于面向C端,通常会使用类似“Qwen3-Max / Qwen3-235B旗舰+ Thinking版”的组合。
02 拿什么“尺子”来衡量Qwen3?
使用如下指标来测评Qwen3的水平:
Artificial Analysis Intelligence Index(AA 指数)
AA指数把MMLU-Pro、GPQA、HLE、LiveCodeBench、SciCode 等十几个高含金量基准融合,
最后给每个模型一个0–100 的综合“智能分”。这个分数目前是国际上最常被引用的大模型“总评分”之一。
LMArena / Text Arena(人类盲评Elo榜)
采用大量真实用户不看模型名,只看回答,投票哪一个更好的方法,用Elo评分来排名,更偏“真实使用体验”的维度。
除此以外,还会使用一些单项基准来进行评测:
AIME2025:竞赛级数学;HLE(Humanity’s Last Exam):极难综合考试;LiveCodeBench/SciCode:偏实战的软件工程与科学代码;以及其它经典的MMLU、GSM8K、HumanEval 等。
本次评测主要围绕AA榜+人类盲评榜,再辅以少量专项基准,尽量做到客观公正。
进入“顶级区”,但天花板依旧。
AA指数:按目前公开信息,各主流大模型的AA指数得分可以见下表:
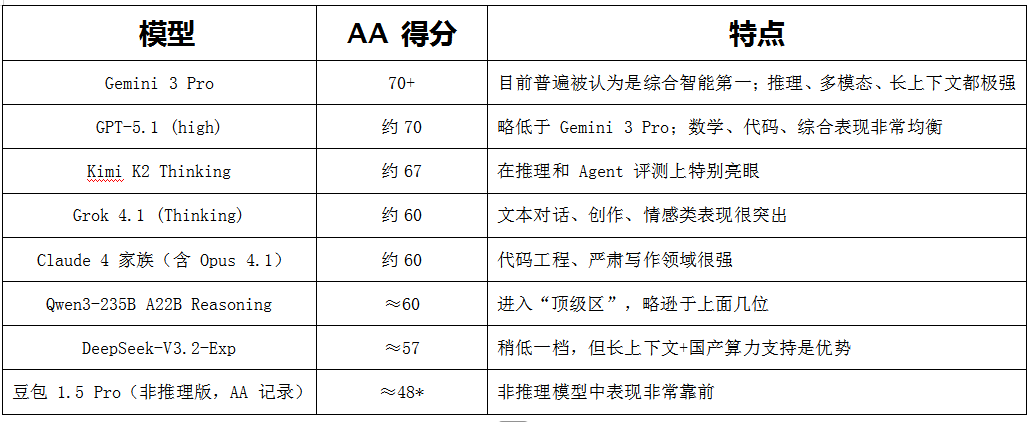
注:在AA《State of AI: China Q2 2025》里被列为“最佳非推理 LLM”之一,分数带星号表示部分基于厂商数据估计
就以上得分看,Qwen3的旗舰版本已经站在Grok 4.1和Claude 4.1的身边,但和Gemini3 Pro、GPT-5.1、K2 Thinking之间,还维持着7–10分左右的差距——这在顶尖模型之间,依然是能感知的差距。
人类盲评Elo榜:评测结果是Gemini3 Pro和Grok4.1(Thinking)轮流占据榜首附近。GPT-5.1、Claude 4家族也稳居头部。Qwen3旗舰的打分虽然略低于这些“榜一大哥”,但确实已经混在第一梯队前列,和它们同一张榜单抢票。
更直观的表述是:真正让海外开发者和研究者投票时,用户已经可以感受到:“Qwen3是强模型,和GPT-5 / Gemini3这一线对比,体验上不会拉开巨大差距。”
再看几个单项评测:
AIME 2025:竞赛数学
测试结果大致排序是:GPT-5 Codex (high) ≈ GPT-5.1 > Kimi K2 Thinking > Grok 4 > Qwen3 235B > Gemini 2.5 / Claude 4 系列。
可以理解为,Qwen3在高难数学上是第一梯队,只是在“竞赛数学+推理特化”的场景中,GPT-5.1 / K2 / Grok 4这些“卷数学的怪物”更强。
HLE:超难综合推理
在这个测试中,Kimi K2 Thinking和GPT-5家族在HLE里表现最扎眼。Qwen3和GPT-4.1/Grok-3/Gemini-2.5 Pro这一代差不多,略有提升。测试结果意味着,Qwen3在极限综合推理上没拉胯,但也不是拿第一的那个。
LiveCodeBench / SciCode:工程代码&科学代码
在工程代码方面,GPT-5.1≳K2 Thinking≳ Grok4≈Gemini2.5Pro> Qwen3≈DeepSeek-V3.2。在科学代码(SciCode)测试中,差距更缩小,大家都在40%多一点的区间里挤。
也就是说,如果你用千问写代码,它的水平大致就是“略弱一点的GPT-5.1 / K2 / Grok4”,但绝不是上一代那种明显掉队。
03 中国四强对比:Kimi、Qwen3、DeepSeek、豆包
Kimi K2 Thinking的综合智能得分约67分,在AA榜上直接冲进全球前五,由于模型专门强调浏览、工具调用、Agent任务,所以在HLE、BrowseComp等偏“代理”的基准上特别强。
Qwen3的综合智能得分60 分左右,各方面比较均衡。DeepSeek-V3.2-Exp的综合智能约57分,特点是国产芯片适配、长上下文性能、推理能效方面做了优化,为中国算力环境量身定制。
豆包1.5 Pro(非推理版),AA China Q2 报告中给出的智能指数约 48*,在非推理模型里属于头部,且被列为“最佳非推理大模型”之一;但其推理版(Thinking)目前还没有完整的AA综合分公开。
综合分数上:K2 Thinking > Qwen3 > DeepSeek-V3.2 >豆包1.5Pro。但如果从“算力成本+国产芯片环境”出发,DeepSeek就有独特位置,而Qwen3则在“生态+稳健通用能力”上更加均衡。

04 用户的视角
日常问答、写作与知识检索
对中文/中英混合的日常用法来说,Qwen3 + 千问App 基本已经是世界级的体验之一。回答速度、知识覆盖、上下文记忆、写作风格都很成熟。和GPT-5.1 / Gemini 3 Pro相比,差距主要在极限长链推理和一些特定专业英文领域。豆包则在自然中文表达、口语化对话、社交媒体语境下的风格更自然,适合做聊天、轻量问答和内容创作。
数学&竞赛级题目
如果用户的使用场景是:竞赛数学、高级逻辑题、极端复杂链式推理等,GPT-5.1、Gemini 3 Pro、Kimi K2 Thinking、Grok 4.1 目前仍然略强。
代码开发
Qwen3 在LiveCodeBench / SciCode 这类基准上的表现,已经是“工程可用”的一线水平。真正大规模做代码重构、复杂调试时,GPT-5.1、K2 Thinking、Grok4在一些数据里略有优势,但Qwen3+好的工具链(IDE插件、CI集成)足以支撑绝大多数团队的日常开发工作。
多模态、文档和表格
这一块是Qwen家族的强项之一:Qwen2.5-VL和Qwen3-Omni在图像理解、PDF/文档解析、表格/图表任务上,经常在论文和评测里拿高分。对用户来说意味着你把PPT、PDF、扫描件、复杂报表丢给千问,它一般能看得比较明白。
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。


