大模型争霸的下一站:不仅是超越GPT-4


文 | 智能相对论
作者 | 沈浪
知名科学杂志《Nature》发表了一篇关于大模型规模参数大小争议的文章《In Al, is bigger always better?》——AI大模型,越大越好吗?随着大模型应用走向实践,这一问题不可避免地成为了当前AI行业发展的焦点与争议。
有人认为,大模型当然是越大越好,参数越大,性能越优。也有人认为,小模型更好,消耗更小,更能精准地解决专业问题。两相对比之下,各有各的道理,悬而未决,究竟什么才是AI大模型发展的出路?
这一问题或许在日前商汤科技举办的技术交流日活动上有所解答。在活动现场,商汤科技发布了行业首个“云、端、边”全栈大模型产品矩阵,以满足不同规模场景的应用需求,对大模型的场景应用提出了新的思路,并且全新升级了“日日新SenseNova 5.0”大模型体系,综合能力全面对标GPT-4 Turbo。
当然,在当前节点上,领先的意义已经不仅仅是超越GPT-4,更是探索出能解决实际应用问题的有效路径。
01、离谱or靠谱?日日新端侧大模型“暴打”GPT-4
在技术交流日活动的现场,商汤科技以一个很有趣的画面阐释了大模型与小模型之间的差别。基于拳皇游戏的画面演示,商汤科技将自家的SenseChat-Lite 版本日日新端侧⼤模型与GPT-4进行PK。
一开始,GPT-4还能略占上风,但是SenseChat-Lite出拳速度更快,随后各种连招打到他根本反应不过来,只得被商汤科技的模型“暴打”,直接K.O出局。

这一结局似乎太离谱了?商汤科技对此做了解释:实际上其中的差距并非模型能力强弱问题,而是在不同的适用场景之下小模型决策速度快。当大模型还在计算的时候,小模型已经完成了判断并且出拳了,而且实实在在打到了对手身上。
正所谓,“天下武功,唯快不破”!对比大模型,小模型在具体的场景应用中有着更明显的决策优势。
因此,业内正在形成一个全面的共识:在实际应用中,大模型并非越大越好,而是得看具体场景需求。前不久,美国AI公司Anthropic发布Claude 3系列模型,一度超越GPT-4,登顶全球最强大模型。其中Claude 3系列就给出了不同量级的模型产品,包括Claude 3 Haiku、Claude 3 Sonnet和Claude 3 Opus,以便适用于不同的企业和场景。
同样的,基于这一思路,商汤科技也在搭建完善的基模型体系与小模型系统方案,并发布了一系列的垂类大模型和端侧大模型。其中,SenseChat-Lite版本端侧大模型就可以面向手机、平板、VR 眼镜、智能汽车等提供轻量、高效的大模型能力,结合端云解决方案,及时适应变化的环境和需求,保持高性能和准确性。
对比来说,中国更注重实践。商汤科技在这个思路上给出的解决方案更具有主动性和服务意识以及更有实践价值。具体的,商汤端侧大模型不仅是参数量级小,还讲究端侧部署与端侧处理能力的强化,在解决实际问题上响应更快速。
与此同时,商汤科技还面向金融、代码、医疗、政务等多个领域推出了边缘产品“商汤企业级大模型一体机”,在实际场景应用中更能满足专业化需求,主动贴合客户需求。比如,“大医”医疗健康大模型一体机就可以在医疗机构内部一键部署大模型应用,实现“开箱即用”,并有效针对智能问诊、导诊、病历结构化、影像报告解读等场景,支持智能调整回复内容的语言风格、详略程度、格式要求等。
当然,这也是目前商汤科技在AI大模型领域领先行业的关键点。同样的思路,以小模型为应用焦点,商汤比别人多走了几步,提出了软硬兼顾的解决方案。
02、在尺度定律之下,没有永恒的“最强”,唯有“日日新”
从经济性而言,小模型更利于企业应用与解决实际问题。那么,是否对于AI行业而言,就不需要训练大模型了?
实则不然。
在技术交流日活动现场,商汤科技提到了一个同为业内共识的理论:尺度定律。在普遍的认知中,以尺度定律为参考,随着模型的参数变大、数据量变大、训练时长加长,则算法性能会越来越好。
OpenAl于2020年曾发布一篇论文《Scaling Laws for Neural Language Models》,其中也有类似的观点,即模型性能随着模型参数大小的增长而变好。因此,在后续的大模型迭代中,OpenAI通过构建一个巨大的海量数据集,再简单增加GPT模型的深度,就做出了具有惊人的涌现能力的大模型产品。
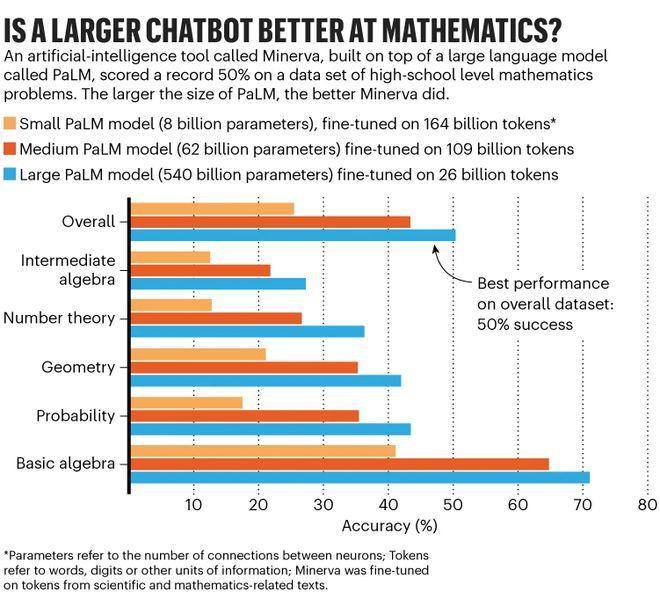
对此,很多厂商也作了相关验证,包括谷歌、商汤科技等。其中,谷歌曾精调了三个尺寸的Minerva模型,分别使用了80亿,620亿和5400亿个参数的预训练PaLM模型。
结果发现,Minerva的性能随着规模的扩大而提高。在整个MATH数据集上,最小模型的准确率为25%,中型模型达到43%,最大模型突破50%大关。
由此,基于尺度定律的认知,他们发现自家的模型产品在一定测试级上超越GPT-4的能力,并非不可能。如今,商汤科技发布的最新的“日日新SenseNova 5.0”大模型体系,其性能就超越了GPT-4。
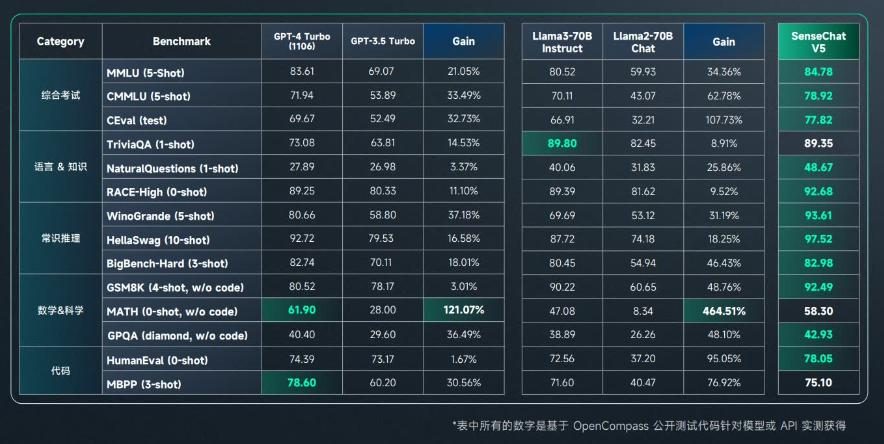
其中,日日新·商量大模型5.0主模型在语言、知识、推理、数学、代码等领域的能力,在主流客观评测上就达到或超越了GPT-4 Turbo,在聊天、多轮对话、信息提取、写作等场景能和GPT-4 Turbo相媲美。
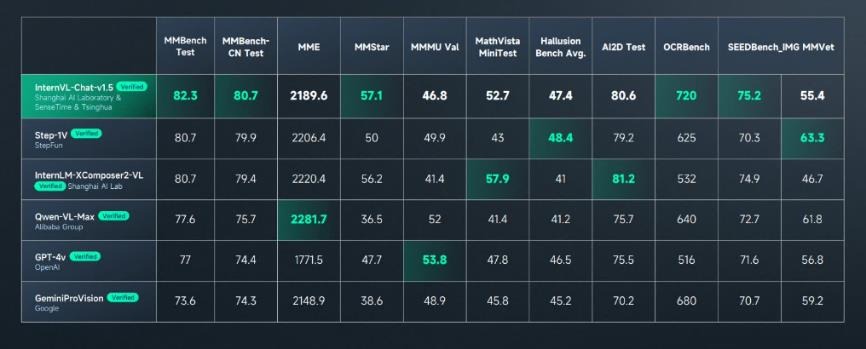
更值得一提的是,日日新·商量多模态大模型的图文感知能力达到了全球领先水平,在多模态大模型权威综合基准测试MMBench中综合得分排名首位,并在多个知名多模态榜单MathVista、AI2D、ChartQA、TextVQA、DocVQA、MMMU 取得领先成绩。
换句话说,在尺度定律的认知下,GPT-4被超越是迟早的事情,AI大模型领域没有永恒的“最强”。
当然,若要登顶最强,虽说可行,但绝不简单。大模型的参数争议,其中就有能耗的问题。谷歌曾坦言,PaLM的训练在2个月内消耗了大约300个美国家庭一年的电力消耗,其中所需要的算力、数据等基础设施绝非常规企业可以负担。
在这一点上,商汤科技秉持“大模型+大算力”的“双轮驱动”战略布局又一次为其拓宽了道路。其中,SenseCore商汤大装置作为商汤科技前瞻决策所打造的高效率、低成本、规模化的新一代AI基础设施,可以支撑超过20个千亿超大模型同时训练,并支持万亿参数大模型的全生命周期生成,为大模型的打造提供了非常关键的支撑。
简单来说,虽说有尺度定律作为理论支持,但是以SenseCore商汤大装置为代表的大算力才是商汤科技能超越GPT-4的底气。从这个角度来看,商汤科技做AI,比大多企业要更加纯粹且彻底。
03、大模型的最优解,是场景平衡
从国内外的实验与实践来看,模型的大小之争意义不大,离开基础理论和场景应用去抛弃任何一方都不可取。因此,目前主流的AI厂商在迭代和发布系列模型时,往往都会推出主模型与小模型以及垂类专业模型,根据场景需求按需提供服务。
这一点将在接下来的时间里拉开专业AI服务商之间的差距。目前,日日新SenseNova5.0大模型体系采用了混合专家模式,这样做的目的在于通过将模型分割成多个具有专门功能的模块,使得模型在推理过程中能更有效地利用计算资源,并可能提高模型的泛化能力和应对复杂任务的性能。
具体来看,商汤琼宇发布的3D高斯泼溅技术,就具备轻量化的web渲染能力,可以产生更轻量的模型资产,使城市级三维模型的构建和编辑重建效果更加真实,成本更低,也可以应用在更多场景。
这是混合专家模式思想在实际应用中的体现,通过不同技术和模型组件之间的配合,实现了对特定任务定制化处理和资源优化,从而加速大模型在不同场景中的应用,实现AI普惠。目前,琼宇已服务客户超过60个,实现了15个城市120多种场景的重建。
因此,当我们把目光投递到实际中的场景问题,就会发现大模型和小模型均有用武之地,问题则在于如何去平衡地调配资源,实现最优解。由此来看,商汤科技对混合专家模式的应用,可以视为是一种领先行业的熟练决策。
未来不属于大模型或小模型,而是大小模型之间的平衡。因此,“AI大模型是否越大越好”类似的问题不必纠结,但需要面对,即如何去打造大模型,又如何把大模型的能力调配出小模型服务好市场,会是各大厂商接下来的必修课程。
*本文图片均来源于网络
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。

