模型是入口,云是腹地:大多数人低估了谭待的决心


2026年,中国AI云市场上同时出现了两个“第一”。但两个“第一”指向的,是截然不同的问题。
Omdia 5月19日发布的报告给出了第一个答案:2025年中国AI云市场总规模567亿元,阿里云以38.1%的收入份额位居第一,超过第二至第四名的总和,在AI IaaS和MaaS两个细分领域均居领先位置。
但在Omdia发布数据的前一周,IDC公布了另一组数字。IDC数据显示,2025年中国公有云大模型调用量同比增长16倍,达到1944万亿Token。在这张榜单上,火山引擎以49.5%的调用量份额、40%以上的营收份额,站在了第一位。
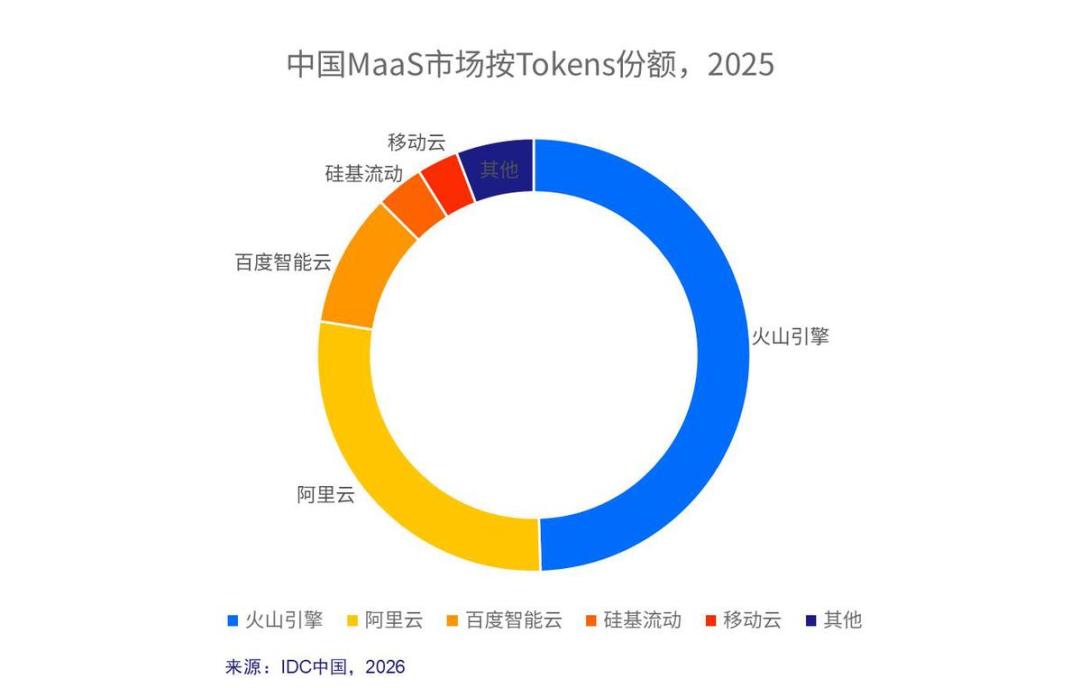
Omdia说的是“谁卖得多”,IDC问的是“谁被用得多”。两份报告,两把尺子,量的是不同维度的东西,但共同印证了2026年中国云市场的繁荣,也精准映出两家公司不同的战略落点,阿里云在收入体量上守住了既有优势,火山引擎则在调用规模上建立了自己的坐标,并试图把量的积累转化为平台层更难被替代的价值。
5月11日,火山引擎发布了国内首个Agent Plan。套餐里,GLM-5.1和Kimi-K2.6与火山引擎自研模型并排陈列,统一使用AFP(Agent Flow Pricing)计费,月费40元起。一家占据中国公有云MaaS市场近半调用量的公司,主动把竞争对手的产品放进了自家货架。
目前,主流模型之间的能力差距,已经收窄到大多数企业用户难以在实际业务中感知的程度。Token单价持续压缩,用户切换供应商的成本趋近于零。在这样的市场条件下,“最强模型”的叙事价值在加速衰减,而“最全平台”的战略优先级随之上升。
Agent Plan是这条逻辑走到今天的产品化表达,而非起点。IDC的数据从规模维度坐实了这个判断,2025年中国公有云MaaS调用量同比增长16倍。在一个量级扩张如此剧烈的市场里,决定天花板的,或许从来都不是模型能力的绝对高度。
低价Token,先把规模跑出来
火山引擎拿下MaaS近半市场份额,靠的不只是模型能力,其比同行更早完成规模积累,并将规模转化为可持续的工程优势。这套逻辑的起点,是一个相对清晰的战略判断——公有云存量市场的格局已经固化,新兴的MaaS业务,才是仍有空间建立差异化的方向。
2020年,火山引擎正式对外推出。谭待接手时,传统IaaS领域早已是一场拼客户粘性、拼多年运营积累的消耗战,后来者几乎没有逆转空间。MaaS因此成了火山引擎最有可能实现突破的方向,先以模型服务建立入口,再带动IaaS和PaaS层的协同增长。
这个逻辑在海外有现成参照。Azure出售OpenAI模型API,只是链条的第一环。企业客户一旦接入大模型,往往会继续采购检索、数据库等配套云服务,整体支出随之抬升。
2020年底,他随字节跳动对“幺零贰四”的收购加入,最初主导火山引擎技术架构,此前深耕搜索引擎领域。相比“提供最聪明的答案”,搜索的竞争逻辑更倾向于“让用户以最低成本、最高效率找到结果”。这个基因直接塑造了他对MaaS的理解方式,即Token是需要以最高效率送达用户的生产资料。
据《晚点LatePost》报道,火山引擎在2025年内两度上调MaaS收入目标,Seed 2.0和Seedance 2.0发布后再次上调,原定超百亿的2026年目标随之刷新。资源的集中方向与调整节奏,始终指向同一个优先级。

谭待曾明确表示,Token使用量高速增长的核心驱动力,是AI视频创作的爆发与AI智能体的加速普及,而非通用语言模型能力的整体提升。这个判断,在豆包大模型的市场表现与其基准测试能力之间存在落差的背景下,多了一层解释力。
在视频生成这一Token消耗密度最高的场景,字节跳动目前处于市场领先地位。据AI普瑞斯报道,按日均算力消耗占比测算,Seedance已占据超过80%的市场份额,可灵紧随其后约占14%,万相约占4%。也就是说,当下的AI视频生成市场,用户每发起10次生成请求,超过8次流向Seedance。
AI智能体场景同样是Token消耗的放大器,一次Agent任务通常包含多轮推理、工具调用与任务执行,单次消耗量远高于普通对话。这个场景结构,构成了理解火山引擎市场份额的第一个关键前提,它的调用量领先,很大程度上建立在特定场景的需求密度上。
而价格机制则是火山引擎规模积累的杠杆。去年5月,火山引擎把豆包大模型价格打入“厘时代”,豆包1.6首创依据输入长度区间定价,综合成本比同级别模型降低63%。谭待事后的解释只有一句话:能靠技术把成本降下来,就决定一次降彻底。
支撑这次降价的技术底座,是火山引擎较早大规模应用的两项关键工程优化——PD分离与KV Cache。可以用一个更直白的类比理解它们的作用,PD分离相当于把“读题”和“答题”两个动作拆给不同的工位分别处理,让每个环节匹配更合适的算力资源;KV Cache则相当于给推理过程配一本“草稿本”,缓存已经算过的历史状态,避免每次生成新内容都从头重算,两项技术的共同目标,是降低单次推理的显存消耗与计算成本。
这两项技术的收益,高度依赖规模。小规模调用时,维护复杂缓存和调度系统本身也有成本,可能抵消节省下来的算力;规模越大,缓存命中率越高,工程优化的收益才越显著。谭待曾用一个例子描述这种放大效应:1万台服务器利用率优化一个点,与100万台服务器优化同样一个点,收益相差100倍。
当PD分离、KV Cache等技术在行业内逐步扩散,Token价格趋向均一,这道门槛才真正显现。规模不足的跟随者对标低价,往往承受更大的成本压力。调用规模更大的平台,成本空间也更充裕,在价格竞争中也具备更长的持续性。
2025年下半年,是去年竞争最激烈的阶段。竞争对手密集入场,但火山引擎的调用量份额从上半年的49.2%进一步升至全年的49.5%。份额没有下降,反而小幅抬升。这个数字,部分印证了规模优势在当前阶段的防御价值。
模型商品化之后,平台开始定价
Agent Plan的发布,是一个信号。它标志着火山引擎在产品层面完成了从模型分发商,向基础设施提供方的重心转移。
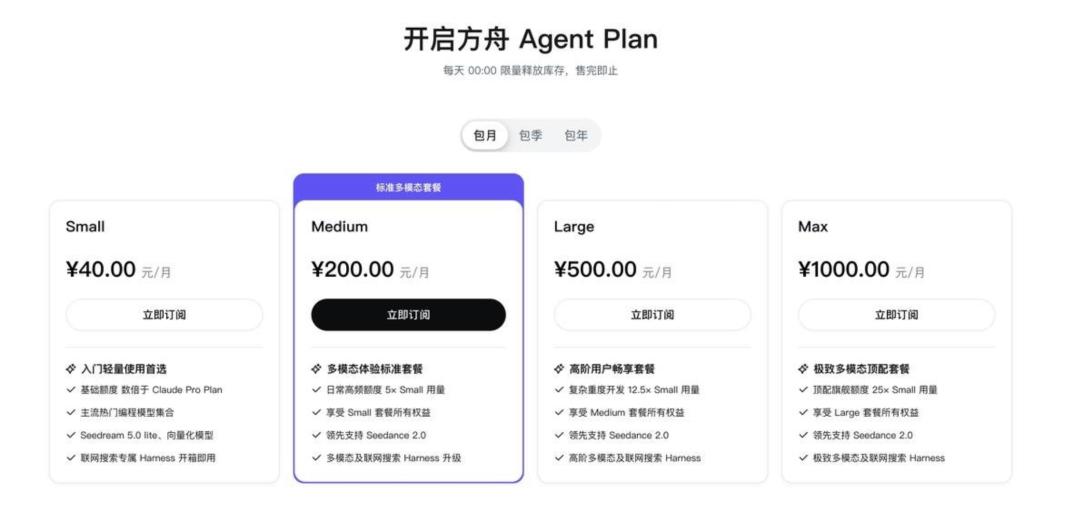
在2026年以前,MaaS的基本商业形态只有一种:卖Token接口。企业按调用量付费,模型是核心购买对象,平台只是管道。Agent Plan改变了这个结构的底层逻辑,将自研Seed系列模型与GLM-5.1、Kimi-K2.6等第三方模型,连同联网搜索等Harness工具打包,以AFP统一计费体系出售。计费单位从“消耗多少Token”迁移到“完成多少任务”。
Harness,是这次发布中被忽视的关键词。MaaS提供稳定的模型能力,Harness负责把推理变成可约束、可追踪、可持续运行的工作流。两者分工不同,但目标却一致,让Agent在生产环境里真正可用。企业的Agent任务通过AFP统一计费平台运行,工作流日志、用量报表和审计记录全部在同一体系内生成时,用户就不得不重点考虑迁移成本。
据《晚点LatePost》报道,火山引擎过去几年的产品演进,在强化MaaS竞争力的同时,也在逐步把大模型服务扩展为覆盖Agent开发与运营的基础设施。谭待此前的描述提供了一个参照:以前写代码,本质上是在写if-else定义工作流;现在基于模型开发Agent,流程规划、任务拆解、创建子Agent等环节,越来越多地交给模型自己完成。
Agent Plan把竞品模型纳入自家套餐,一种解读是火山引擎判断自身的基础设施价值,已经高于单一模型的产品价值,可以从第三方模型的分发中获取渠道收益,逻辑类似AWS Marketplace允许第三方SaaS软件上架,平台的核心资产是用户在平台内积累的工作流数据与账单绑定深度。
这里有一组方向相反的力量在同时运作,把竞品模型纳入套餐,降低了用户在平台内切换模型的摩擦,是一种开放姿态;AFP统一计费的设计目标,恰好相反,它在提高用户离开这个平台的整体成本。开放性吸引用户进来,账单绑定让用户留下。哪个目标最终占主导,取决于企业客户对平台的依赖深度。而这个深度,只有当真实的Agent工作流被部署进生产环境之后,才能被测量。
目前检验这个判断的关键变量只有一个,那就是第三方模型在Agent Plan总调用量中的占比,是否会随时间持续下降。如果用户最终向Seed系列集中迁移,平台化叙事成立;如果比例稳定甚至上升,则更接近一种现实主义的能力补位。答案需要时间。
支撑平台化转型的,还有组织结构的同步收敛。2025年,字节跳动AI研发团队经历了三次整合,AI Lab整体并入Seed团队,视觉生成团队与豆包技术部的管理权限统一纳入Seed体系,从分散研发走向统一驱动。这不只是研发效率的整合。只有统一调度的研发体系,才能为MaaS平台提供稳定、可预期的模型迭代节奏。
火山引擎已经回答了MaaS第一阶段的核心问题,即胜出不需要最强的模型,需要的是最低的调用门槛、最彻底的价格策略,以及比对手更早完成规模积累。但规模优势只有被转化为平台层的绑定深度,才能延续到下一阶段的竞争。而平台绑定的前提,是企业客户真正把Agent工作流跑在这里,这要求工具链的完整度和模型能力在关键场景上足够可靠。
写在最后
从Token平台到Agent基础设施,这条演进路径在海外有轮廓可循。Anthropic与多家云厂商合作,OpenAI与AWS合作将模型封装进云平台的原生Agent环境,目标都是让企业能在云平台内完成生产级Agent的开发与运营。IDC报告显示,MaaS的商业边界,正在从“按量计费的推理服务”扩展为“企业AI工作流的运营底座”。越来越多的大客户与平台的合作,开始向业务流程的深处延伸,而不只停留在账单层面。
不过,IDC的预测给出了一个判断,2026年中国MaaS市场Token消耗量将达到40000万亿,对应营收约186亿元人民币。消耗量在一年内扩张约21倍,营收增幅远低于量的增幅。这意味着Token的平均单价将进一步压缩。
量增与价降同步发生,背后是行业在当前阶段的共同选择。先把规模做出来。但低价策略有一条财务底线,算力成本的下降速度,必须能跑赢Token单价的下降速度。这个问题的答案,悬在英伟达的供货节奏和国产替代芯片的成熟进度之间。两者目前都难以精确预判。
谭待说过,MaaS这件事还太早,“马拉松才跑500米,别取得一点点小成绩就满意了。”这句话在2025年是内部激励,在今年5月读来,多了一层别的含义,把竞品模型打包进自家套餐的决定,是一家已在规模竞争中建立优势的公司,对下半程规则可能改变的提前布局。这个判断是否正确,要等企业客户真正跑起生产级Agent之后才能验证。
“够用”赢得了第一阶段。能否用同样的逻辑赢得Agent-as-a-Service的竞争,取决于企业级Agent场景对模型能力的实际容忍边界在哪里,才是下半程真正的问题。
*题图及文中配图来源于网络。
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。

