最强模型也不到50分,两大权威机构新评测给AI Agent泼


出品/未来科技界
作者/
编辑/
过去两年被各种考试捧上神坛的大模型,一旦被拉进真实企业环境,成绩突然不及格了?
5月29日,Artificial Analysis联合IBM软件创新实验室发布了ITBench-AA。该基准建立在IBM研究团队此前推出的ITBench评估框架之上,是业内首个面向企业级AI Agent真实工作能力的测评体系。
在ITBench-AA评测基准下,即便是当前最先进的一批大模型,在模拟企业IT工作场景时,表现依然不算理想。其中,Claude Opus 4.7综合评分47%,GPT-5.5得分46%,Qwen3.7 Max得分42%,没有任何模型突破50%。
所谓Benchmark,可以理解为AI行业统一使用的“考试卷”。过去几年,大模型在知识问答、数学推理和代码生成等测试中不断刷新成绩,但IBM认为,这些测试更多反映的是模型的答题能力,而非工作能力。ITBench-AA正是在这样的背景下诞生。
ITBench-AA试图把考场搬进真实的工作环境,测试AI是否能够像工程师一样排查故障、处理安全问题和优化云资源成本。换言之,ITBench-AA模拟的是企业真实的运维环境。
测试覆盖了三类典型企业场景。
第一类是SRE(Site Reliability Engineering),即运维与系统可靠性。这是企业最常见的技术岗位之一。当网站无法访问、应用突然报错、数据库连接异常时,运维工程师需要查看日志、分析监控数据、检查系统配置,并逐步定位故障来源。
第二类是CISO(Chief Information Security Officer)相关场景,即安全与合规管理。企业每天都面临大量安全风险。从权限配置错误到潜在漏洞暴露,再到不符合监管要求的系统设置,都可能带来严重后果。企业的安全管理员需要检查系统配置、识别潜在风险,并提出整改建议。
第三类则是FinOps(Financial Operations),即云成本管理。随着企业越来越依赖云计算,如何控制云资源开支正在成为新的管理难题。如何分析资源使用情况、识别浪费环节并提出优化方案是企业必须具备的能力。
三类场景看似各有侧重,但有一个共同点:它们都要求Agent在真实、动态、信息不完整的系统环境中独立完成一项完整的工程任务。需要说明的是,ITBench-AA本次发布的评测结果聚焦于SRE领域,CISO与FinOps场景将在后续轮次中陆续发布。
那么,这些在代码测试中表现优异的“学霸”模型,进了企业考场后却集体“水土不服”,究其原因可以从两个层面来理解。
第一个层面是评分标准本身的严苛程度。ITBench-AA采用“完全召回率下的平均精度”作为评分标准,所谓召回率,就是AI找出的根因占所有真实根因的比例。而“完全召回”意味着AI Agent必须找出所有导致故障的根本原因,不能遗漏任何一个。如果一个Agent找出了90%的原因,但漏掉了一个关键的根因,那么该测试项的评分就是0。这种评分方式反映的是企业生产环境的真实要求:在金融、医疗、航空等场景中,“差不多”的答案和“完全错误”的答案一样不可接受。
第二个层面在于模型自身的执行能力缺陷。报告显示,不同模型完成任务所需的交互次数差异巨大。GPT-5.5平均每个任务需要约31轮操作,而Gemini 3.1 Pro平均达到83轮。但更多操作不意味着更高成功率,研究人员发现,许多模型的问题并不在于找不到信息,而在于无法从海量信息中筛选出真正关键的线索。
真实企业环境每天都会产生大量日志、监控数据和告警信息。故障原因往往隐藏在成千上万条记录之中。对于人类工程师来说,经验能够帮助其快速排除无效线索;但对于Agent而言,如何从复杂环境中筛选有效信息,是一项艰巨的任务。
评测报告揭示了一种典型的失败模式:“过度诊断”。调查得越深入,AI反而越容易“想太多”,把一些本不相关的系统异常或临时性报错也误判为故障根源。这在困难级别的场景中尤为突出。
ITBench原论文还发现了一个值得注意的细节:当Agent能够访问链路追踪数据时,GPT-4o的诊断成功率从9.5%提升到13.8%。这说明更好的可观测性工具能显著提升AI Agent的表现,也暗示了未来优化的一个方向。
尽管整体成绩不高,但测评的榜单中仍然出现了一些值得关注的趋势。
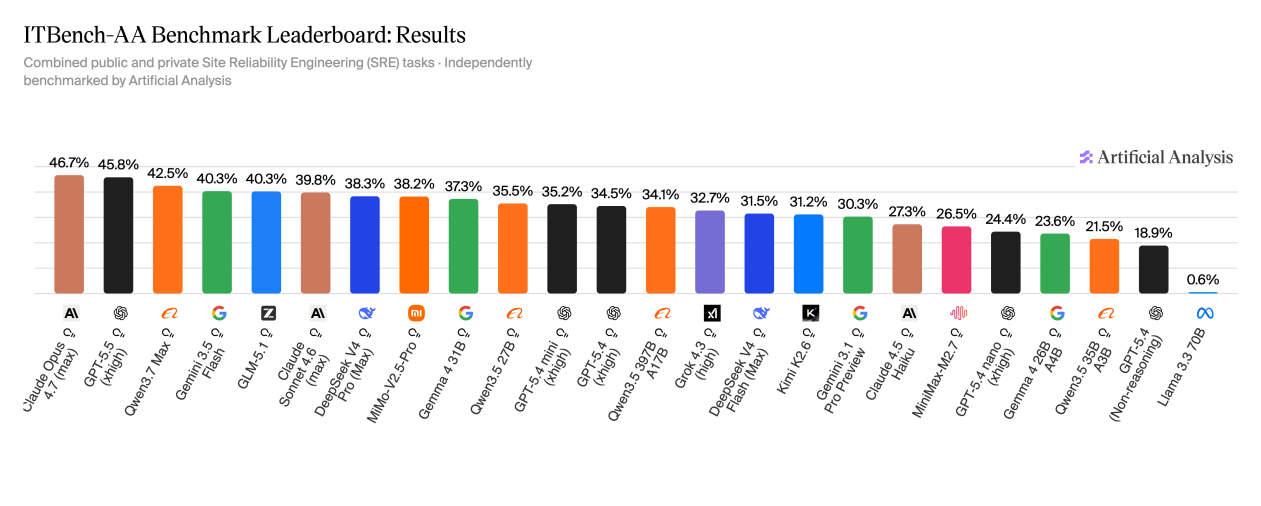
虽然Claude和GPT仍然占据榜单前列,但开源模型与闭源模型之间的差距正在缩小。在本次评测中,GLM-5.1以40%的得分成为开源模型中表现最好的模型之一。值得关注的是Gemma4 31B,得分37%,但单任务成本仅为0.14美元,约为GPT-5.5(5.38美元)的三十八分之一。两者得分差距不足10个百分点,性价比优势明显。
对于企业来说,模型选择不仅取决于准确率,还取决于部署成本、推理费用以及可定制能力。开源模型的优势不仅在于价格:企业可以私有化部署,敏感数据不出内网,这对于金融、政务等行业尤为关键。
同时,企业可以根据自身运维环境对模型进行微调,而闭源模型只能通过提示词工程来适配。也就是说,当开源模型能够以更低成本提供接近的能力时,其商业价值也将进一步提升。
整体看,ITBench-AA给行业提出了一个新的问题:当大模型逐渐刷完了所有容易量化的考试,下一阶段该如何衡量它们的价值?
过去,大模型最大的挑战是获得能力;如今,更大的挑战是把能力转化为生产力。从标准化测试到真实业务流程,中间仍然隔着一段漫长的“最后一公里”。
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。


