从训练算力到推理算力,CXL从可选走向必选

根据韩国媒体THE ELEC近日援引业内人士消息报道称,三星电子计划于今年六月后第三季度向主要服务器和数据中心客户交付基于CXL 3.1协议的CMM-D内存模块样品,如果客户资格审查顺利进行,目标今年四季度实现大规模量产。

图片说明:三星电子目标在今年第四季度实现基于CXL 3.1协议的内存产品量产,数据来源于THE ELEC
根据澜起科技(688008.SH)在5月15日公告的《投资者关系活动记录表》,公司预计今年是CXL规模化部署的起点,预计到2027年将进入CXL规模商用的元年。澜起科技的关于CXL放量的时点判断与三星电子基本一致。
当行业内两大巨头行动一致之际,意味着CXL的拐点即将到来。CXL(Compute Express Link),一个在过去被定位为“可选”的技术协议,正在加快速度朝着“必选”的方向迈进。

图片说明:澜起科技关于CXL规模化商用的时点判断,数据来源于澜起科技
推理算力短缺,衍生出来了新的问题
同样是算力短缺,但2026年以来的算力短缺与之前的算力短缺有点不太一样:
在2026年以前,北美云计算企业们和独立大模型企业们(如Anthropic、OpenAI等),整日都在进行军备竞赛,企业们为了训练出更好的AI大模型而疯抢算力卡,进而造成算力短缺,算力短缺的矛盾集中在训练端。
而过去解决训练算力短缺,主要采取的方法是提高GPU的单卡算力更高,同时采用新的互联技术和互联架构,让算力卡和算力卡之间(例如Scale up场景)、机架和机架之间(例如Scale out场景)等等,能够更加高效的用光通信技术互相连接起来(如光模块方案、CPO方案等等)。
然而2026年以来,随着Agentic AI的出现、以及Coding、多模态等为代表的AI应用普及,token需求暴增,算力短缺的矛盾正在迅速向推理端倾斜。
推理算力短缺,会衍生出来一系列新的问题,这与训练算力短缺的解法,并不完全一致。
在Transformer架构的AI大模型(如豆包、Deepseek)输出文本时,输出方式是一个token一个token往外“蹦”的,每输出下一个token,都必须结合之前所有的上下文。为了避免每次生成新的token时都把前面所有的token重新计算一遍(那样计算量太大了),因此人们设计了一种“偷懒”的方法,把上下文的一些特征缓存下来(即Key和Value向量),形成一个类似于“记事本”的东西,这样就避免了重复计算,这个“记事本”被称作KV Cache(键值缓存)。
在Agentic AI出现以前,AI推理主要是一问一答的Chatbot模式,例如问豆包,“帮我复盘一下今天A股的市场行情,并帮我写一个简要的总结”。一般来说,豆包会在几秒内生成答案,输出的答案即token,大约几千个。如果继续问其他问题,上下文token就几千个、最多几万个,KV Cache占用并不明显。
但是用Agentic AI就完全不一样了,同样的问题,token可能会产生几十万甚至上百万个,因为Agent AI在解决问题时,会使用ReAct(思考-行动-观察)框架,它会调用搜索工具、运行代码、报错后自我纠正。这个过程中,每一轮的中间思考过程和返回的结果,都会被塞进对话历史中,随着任务的推进,上下文就像滚雪球一样越来越长,对应KV Cache会呈指数级飙升。
例如,去年12月有专业研究团队让Claude Code(Anthropic的Agentic AI编程工具)执行了一个代码修复任务,并对Claude Code的底层运行机制进行了逆向工程和流量追踪,测试结果为:在这个单一的任务生命周期内,用时合计13分钟,token累计消耗量高达约200万个。

图片说明:Agentic AI对token的消耗量是巨大的,数据来源于论文《Context Engineering & Reuse Pattern Under the Hood of Claude Code》
一个Agentic AI任务就可以占用上百万个token,这意味着什么呢?
按照KV Cache的计算公式,100万Token大约会产生320GB的KV Cache(不同大模型有所差异,但大差不差),这就已经超过了英伟达B300单卡配备的12层HBM3e的总显存容量288GB。
因此问题是清晰的,在Agentic AI时代,仅靠HBM的显存是远远装不下KV Cache的。

图片说明:KV Cache的计算公式,数据来源于Meta
解决HBM显存不足的方法
面对指数级增长的KV Cache,目前有以下几种解决方法:
第一种方法,是增加HBM显存容量。例如Rubin Ultra原本计划采用16层堆叠HBM4e显存,容量1TB,近期又传闻因为良率问题,改为12层堆叠,总显存降至768GB。
这种方法是英伟达正在做的,但是一方面HBM很贵,且迭代速度较慢;另一方KV Cache是指数级增长的,HBM显存容量是线性增长的,后者难以追赶前者增长速度,因此这种方法是必须的,但同时是治标不治本的。

图片说明:HBM4e显存遭遇良率问题,数据来源于新浪财经
第二种方法,是通过先进算法去压缩KV Cache。例如Token丢弃算法,用算法来评估那些KV Cache是没用的废话,评估后直接删掉。或者用压缩技术,把原来的16位浮点数采用INT8甚至INT4量化技术来存储KV Cache,相当于把高清图片压缩成马赛克图片,只要模型还能勉强认出马赛克的内容(保证精度不崩),KV Cache的容量就能缩小到原来的1/2到1/4。
这种方法是大模型企业正在做的,但KV Cache的压缩空间始终是有限的,AI Agentic渗透率提高后指数级的增长却是无限的,因此这种方法是必须的,但同时也是作用有限的。
第三种方法,把新的KV Cache装在HBM里,把旧的KV Cache装在DDR5里,把更旧的KV Cache装在企业级SSD里,等到大模型需要回忆这些旧的KV Cache时,GPU再从DDR5或SSD里读取。
相比于HBM,DDR5和企业级SSD的容量非常非常大,且价格也便宜很多很,看起来几乎可以完美解决KV Cache装不下的问题。
但这种方法也面临着一些问题,因为GPU和其他硬件之间没有类似于NVLink这样的高速互联技术,GPU要和其他硬件进行传输,只能通过PCIe(Peripheral Component Interconnect Express)。
简单来说,PCIe是AI服务器内部的一条公路系统,除了GPU和GPU之间通过NVLink高速互联不用经过PCIe外,其他所有的各种数据(指令、图像、文件等)都要通过PCIe在各个硬件之间传输,如GPU和CPU之间便通过PCIe传输。
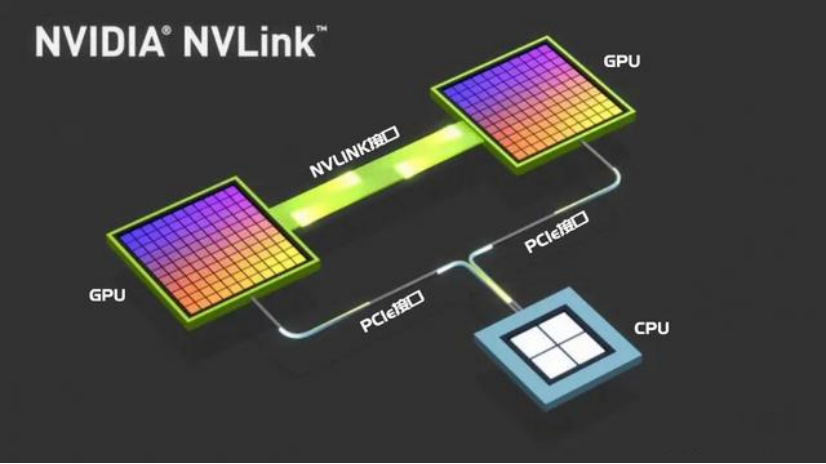
图片说明:PCIe在AI服务器内的作用是连接“异构部件”,如连接CPU与GPU、连接GPU与网卡等,数据来源于超擎数智
问题在于,在PCIe总线协议之下,GPU不能直接调用DDR5里的数据,一定要CPU先把数据从DDR5里复制出来,然后通过PCIe总线粘贴到HBM里,最后再由GPU调用。而SSD的路径就更长,CPU先将数据从SSD里复制出来,通过PCIe总线粘贴到DDR5里,然后重复上面的过程,最后由GPU进行计算。
这样一来一去,是非常低效的,一方面由于可能不止一次经过CPU及复杂的树状拓扑,就会导致延迟;另一方面,PCIe的带宽相比于NVLink的带宽,就不是一个数量级的,这会进一步增加延迟。
延迟的后果是显而易见的:由于运力不足,GPU将经常处于闲置状态,因为大部分时间都在等数据运输过来。
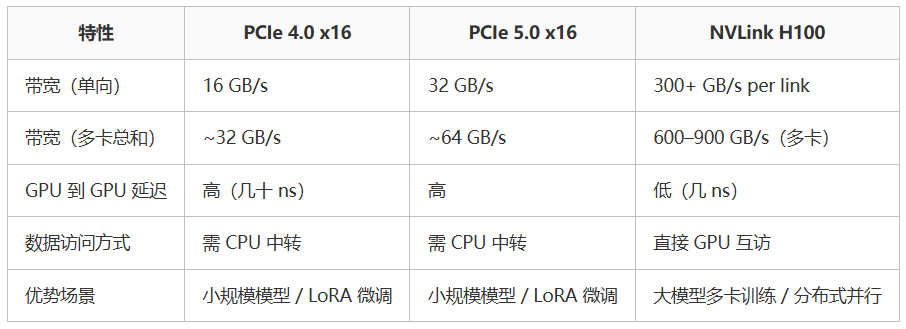
图片说明:PCIe与NVLink比较,数据来源于博客园
CXL是什么?解决了什么问题?
CXL(Compute Express Link),是一种开放性的、行业标准的、高带宽及低延迟的互连协议,CXL建立在PCIe物理接口之上(这意味着不用重新设计AI服务器主板的PCIe插槽),但解决了PCIe解决不了的核心痛点。
CXL包含了三个极其关键的子协议:
第一个是CXL.io(配置与控制):相当于传统的PCIe,负责设备的发现、连接、报错、配置等基础工作。
第二个是CXL.cache(缓存一致性):允许GPU直接访问CPU的DDR5内存条,GPU可以直接在原地读取并处理CPU内存里的数据,GPU和CPU看到的都是同一份数据的最新状态(缓存一致性),彻底消灭了复制粘贴、搬来搬去的动作。由于CPU、GPU、ASIC可以围绕着同一个“CXL内存池”协同工作,所有数据被共享,谁需要算谁就算,整个机架上的所有芯片,在逻辑上变成了一台“超级计算机”。
第三个是CXL.mem(内存扩展):允许CPU直接把外接设备(如CXL内存模块)当作自己的原生内存来使用,进而意味着CPU不再受限于主板上的DDR5插槽数量限制,可以通过CXL接口无限外接内存。CPU通过CXL协议,会把这个外接的内存当成DDR5一样使用,系统内存容量瞬间翻倍,而且带宽也大幅增加。
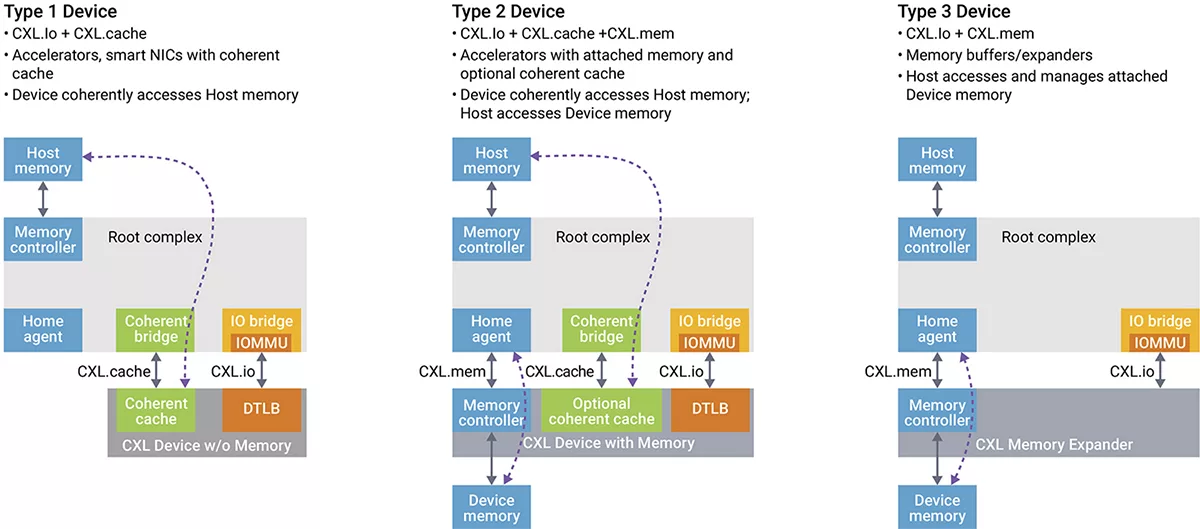
图片说明:CXL.io、CXL.cache、CXL.mem三种协议的调用方式,数据来源于Synopsys(新思科技)
简单来说,CXL最具革命性的能力(在CXL 2.0阶段实现,目前已进入CXL 3.1阶段),是内存池化与动态共享(Memory Pooling & Sharing),由此彻底消灭了内存浪费的问题,根据CXL官方文件,AI数据中心的内存利用率可因此从40%上升到80%,省下了海量的采购成本。
以下图为例,CXL 2.0 Switch上面是多个GPU、下面是多个存储芯片,左图GPU H1正在调用D2和D3的数据,右图GPU H1正在调用D1、D2、D4的数据,同时D2的数据也正被GPU H3调用。
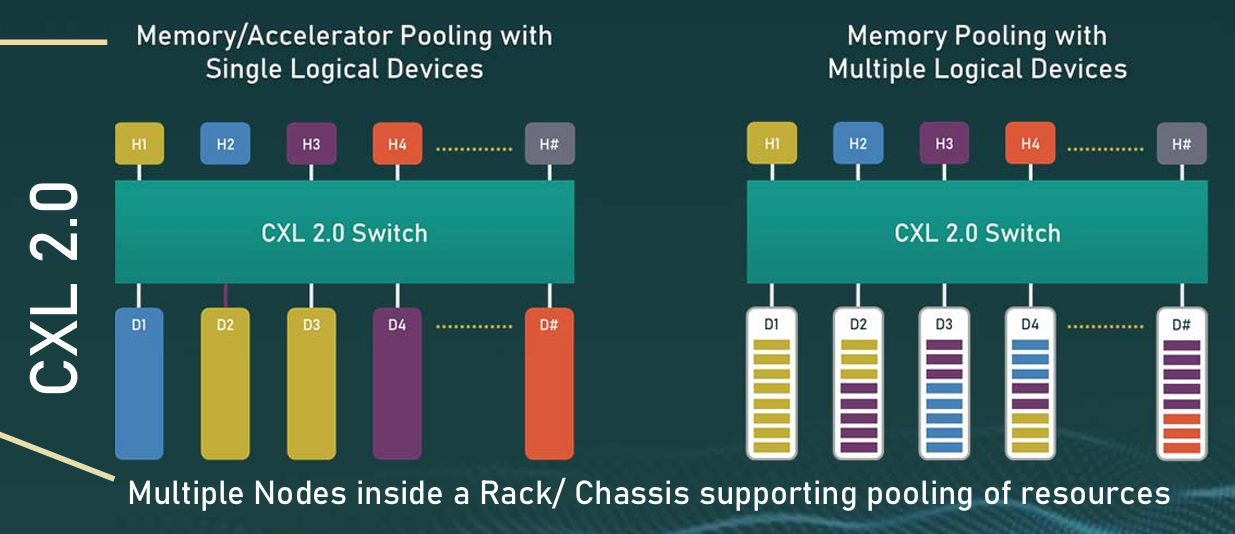
图片说明:CXL内存池化的示意图,数据来源于CXL官网
总的来说,CXL不仅仅是一个基于PCIe的新协议,甚至可以说是AI服务器在底层架构上的一次重构,它把过去“以GPU为中心、各自为战”的服务器,变成了“以数据和内存为中心、高度池化共享”的新型算力架构。或许这是为什么在AI推理算力爆发的今天,芯片巨头们(英伟达、三星、澜起科技、Astera Labs、阿里、华为等等)都在押注CXL的原因吧。

图片说明:CXL协议成员,数据来源于CXL官网
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。

