反其道而行之的DeepSeek,AI产业上下游的斩杀线 上篇


5月22日晚间,根据深度求索公司在小红书官方账号的消息,DeepSeek更新了其API文档,新文档显示,DeepSeek-V4-Pro模型的API价格将于2026年5月31日结束2.5折优惠活动后,正式调整为原定价的1/4。这一API的2.5折优惠活动,原定于6月起恢复原价,但最新公告确认,DeepSeek-V4-Pro的API价格将永久降为原价的1/4(相当于2.5折),即:每一百万tokens输入(缓存命中)0.025元,输入(缓存未命中)3元,输出6元。

图片说明:深度求索宣布对DeepSeek-V4-Pro API永久降价,数据来源于小红书
估值之家认为,本次深度求索宣布对DeepSeek-V4-Pro API永久降价,其意义或许被远远低估,因此分为上下两篇进行论述,其中上篇主要论述DeepSeek是如何反其道而行之的,并简要论述反其道而行之的原因、以及对于AI下游大模型行业的影响;下篇主要论述DeepSeek对于AI上游行业的影响,包括但不限于国产算力和北美算力等等。
别人都在主动涨价,只有DeepSeek在主动降价
2026年以来,随着Agentic AI进入初级应用阶段,全球大模型行业正式告别了亏本跑马圈地的时代,无论美国还是中国,均迈入了token通胀的时代,本次DeepSeek宣布主动降价,似乎显得有些格格不入。
首先来看北美大模型市场。
第一个是OpenAI涨价。2026年4月起,OpenAI将其Codex收费模式全面转为直接按API Token抵扣,并于5月初上线了GPT-5.5。目前在GPT-5.5每调用一百万tokens的标准额度,输入消耗125 Credits,输出消耗750 Credits,输入和输出较此前GPT-5.4均实现翻倍(其一百万输入/输出分别对应62.5 / 375 Credits)。

图片说明:GPT-5.5价格较GPT-5.4翻倍,数据来源于OpenAI官网
第二个是谷歌涨价。从谷歌在5月19日举办的最新Google I/O 2026开发者大会以及年初的一系列动作来看,Gemini在开发者API、企业Workspace套件以及C端个人订阅配额三个维度,均实施了不同程度的直接涨价或变相收紧。
例如,谷歌过去将Flash系列(如3.1 Flash Lite和3.0 Flash)一直以极低的价格(低至每百万tokens约0.1美元级别)作为对抗OpenAI和DeepSeek的策略,但在最新发布的Gemini 3.5 Flash,这一策略发生了较大变化。
Gemini 3.5 Flash的API价格被定在每一百万tokens输入1.5美元,输出9美元。这一价格是3.0 Flash的3倍、是3.1 Flash Lite的6倍,这使得3.5 Flash已经逼近了3.1 Pro的价格(3.1 Pro目前为每一百万tokens输入2美元,输出12美元)。
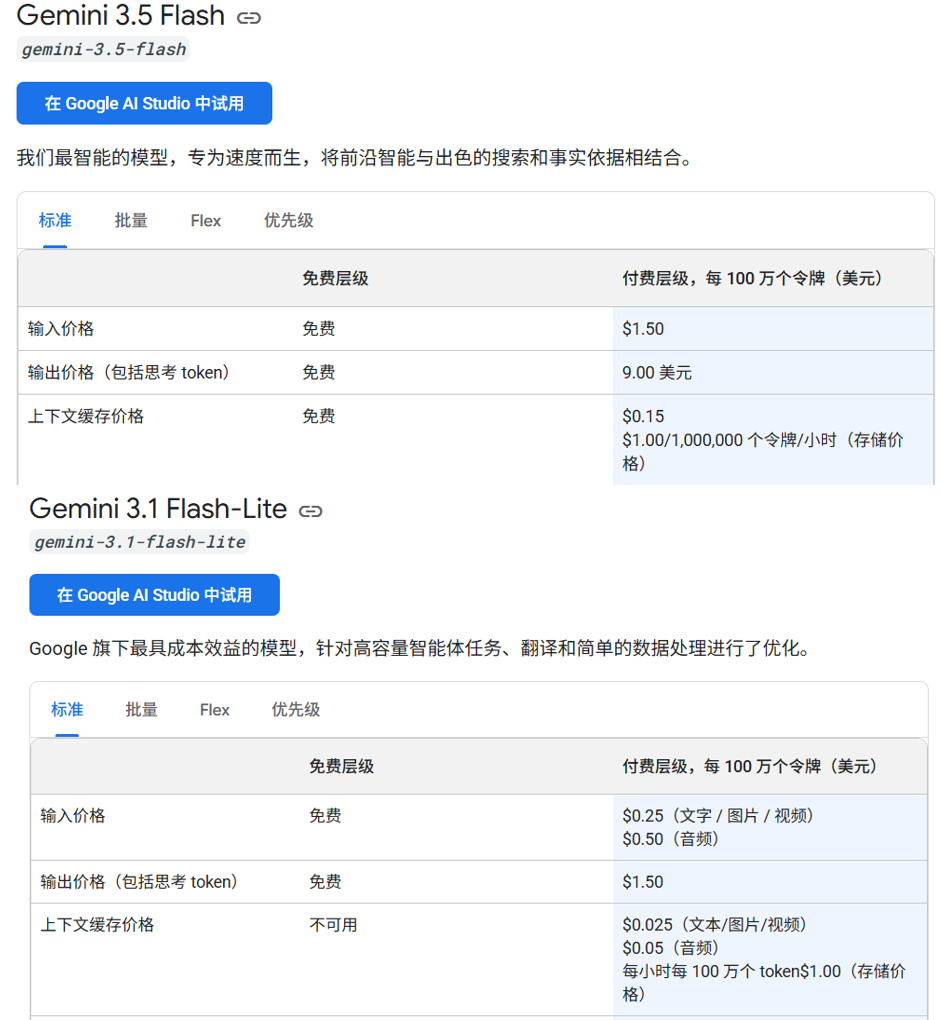
图片说明:Gemini大幅涨价,数据来源于谷歌官网
第三个是Anthropic涨价。Anthropic没有简单粗暴地提高底层每月20美元的Claude Pro订阅价格,Anthropic的涨价手段是行业内最隐蔽、最精准、同时也是涨价最多的。
一方面,根据Anthropic于4月16日发布的最新旗舰Claude Opus 4.7,其价格(每一百万tokens输入5美元、输出25美元)看似没有变化,但在官方白皮书的脚注中,Anthropic引入了新的分词器,会导致相同文本解析出的tokens数量增加约35%(即原来100个tokens的文本,现在变成了135个tokens的文本),相当于变相涨价了35%。
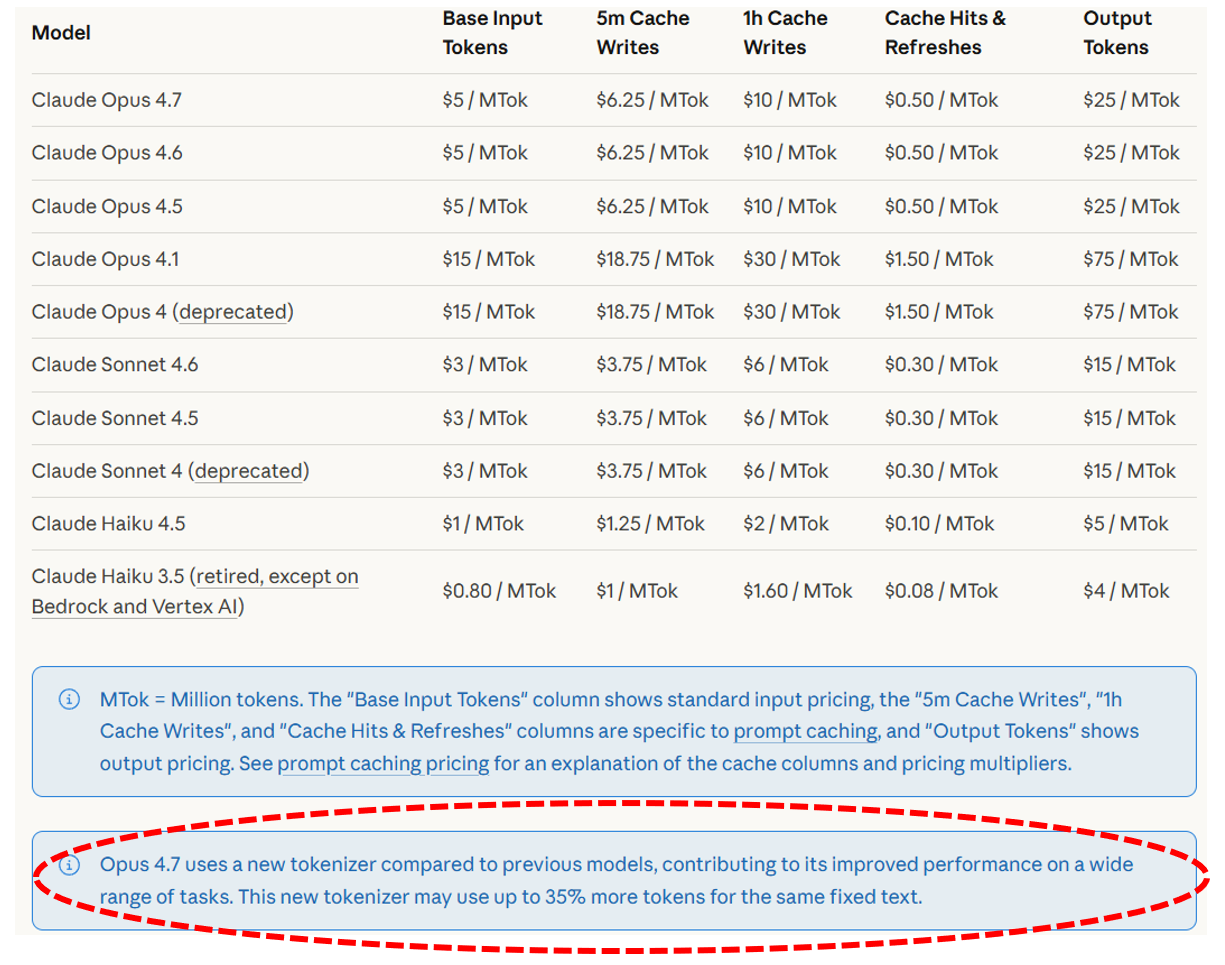
图片说明:Anthropic没有直接涨价,但其采用隐蔽的涨价手段,数据来源于Anthropic官网
另一方面,根据Anthropic公告,自6月15日起,Anthropic将全面引入双轨制,强行将使用场景划分为Human in the loop(即chatbot)与Autonomous(即Agentic AI),针对自主循环的Agentic AI(如Agent SDK、GitHub Actions、claude-p等自动循环),将不再享受订阅包月,而是强制设为专用月度额度制(Agent Credits)。
在施行双轨制的定价规则后,过去大量程序员依靠购买Anthropic每月200美元的Max 20x套餐,在后台24小时不断运行Claude Code,可以产生相当于价值约5000美元的Agent Credits,现在强制转入新的计费规则,订阅包月最多只能产生200美元的Agent Credits,这相当于变相提价了25倍。
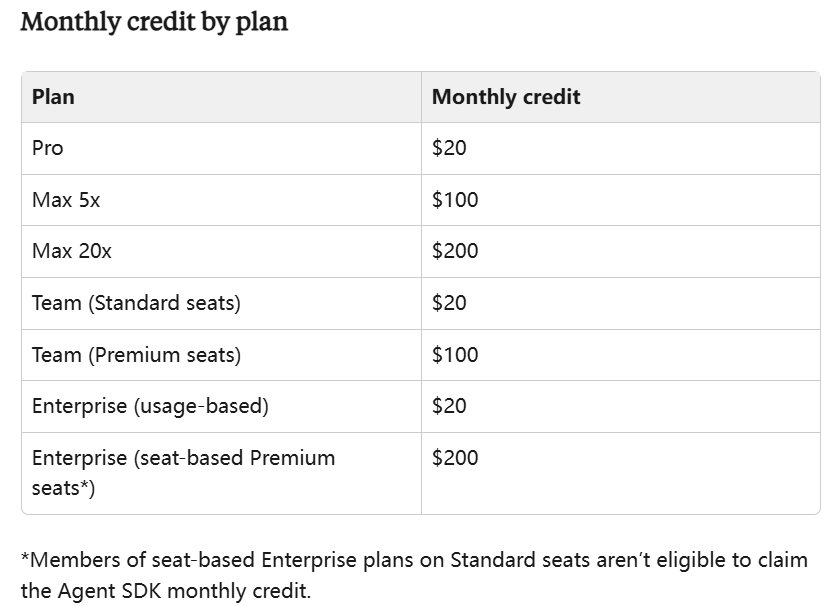
图片说明:尽管Anthropic没有直接涨价,但引入双轨制计费规则后,其涨价幅度却是最多的,数据来源于Anthropic官网
其次来看中国大模型市场。
第一个是智谱涨价。2026年2月12日,智谱(2513.HK)大模型率先发出“GLM Coding Plan”价格调整公告,打响了国产AI大模型2026年涨价第一枪。
国内Coding Plan订阅套餐整体价格上调 30%起(部分档位上调30%~60%),海外市场提价更甚,其在海外发布GLM-5时,配套的Coding套餐价格上涨30%~60%,API基础调用费暴涨67%~100%。
此外,4月8日智谱发布GLM-5.1旗舰时,再次将核心Coding场景下的缓存命中token价格上浮10%,使其高频核心价格首次看齐海外头部产品Claude Sonnet。
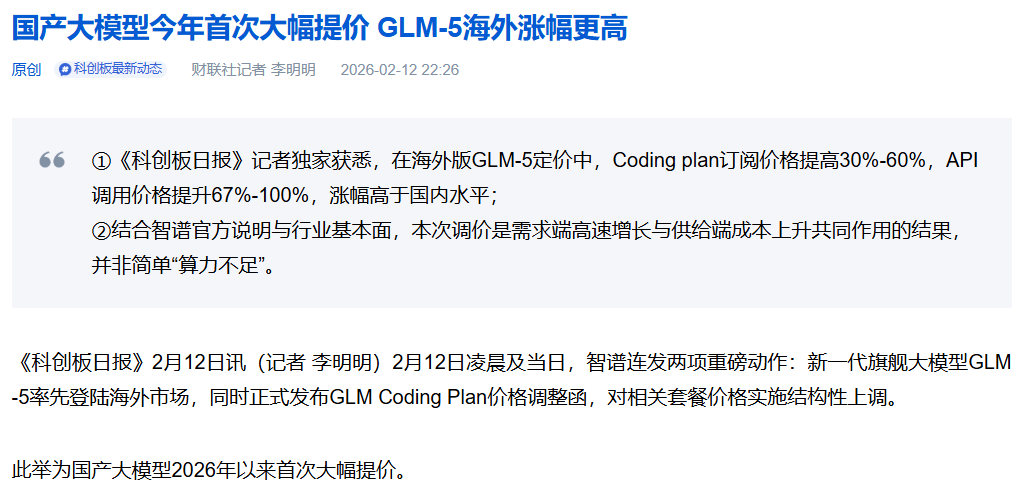
图片说明:智谱打响国产AI大模型2026年涨价第一枪,数据来源于科创板日报
第二个是字节跳动涨价。5月初,豆包App正式上线三档增值订阅服务(标准版 68元/月,加强版 200元/月,专业版 500元/月),虽然仍保留基础免费服务,但在大模型推理算力极度吃紧的背景下,大厂依靠无限免费补贴输送流量的平衡已经彻底被打破。

图片说明:豆包涨价,数据来源于豆包
第三个是腾讯云、阿里云等涨价。腾讯云(0700.HK)于2026年3月13日宣布正式结束GLM-5、MiniMax 2.5(0100.HK)、Kimi 2.5 (月之暗面)在云平台的免费公测,全部转入按量计费。同时,腾讯云将其主打产品混元模型Tencent HY2.0 Instruct输入侧价格直接从0.8元/一百万tokens上调至4.505元/一百万tokens,涨幅达463%。5月,腾讯云再次宣布AI算力相关产品价格上调5%。与此同时,阿里云(9988.HK)5月15日正式宣布上调百炼平台模型服务的基础计费价。

图片说明:腾讯云涨价,数据来源于腾讯云
DeepSeek是在主动发起价格战吗?
对于反其道而行之的DeepSeek,我们不禁要问,深度求索公司的动机到底是什么?尤其对于已经杯弓蛇影的资本市场来说,“内卷”、“价格战”等字眼,无时无刻都在挑动着投资者们早就无比脆弱的神经。
首先,深度求索曾于4月24日发布《DeepSeek-V4预览版:迈入百万上下文普惠时代》,公告中明确表示:“受限于高端算力,目前Pro的服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,Pro的价格会大幅下调。”
一方面,彼时深度求索并没有给出下半年Pro API价格下调的预计幅度,另一方面,现在还没有到下半年,就已经提前宣布降价75%。

图片说明:深度求索4月24日关于DeepSeek-V4-Pro价格的表述,数据来源于微信公众号
绝大部分情况下,在一个行业处于明显的上行期、尤其是上行初期时,企业降价的主要目的还是为了跑马圈地、抢占更多的市场份额,或者因为产品力不足被竞争对手大幅赶超,而不得已采取的策略。但是,以DeepSeek震撼全球的品牌力和产品力,如果出于这样的动机,似乎是完全不合逻辑的。
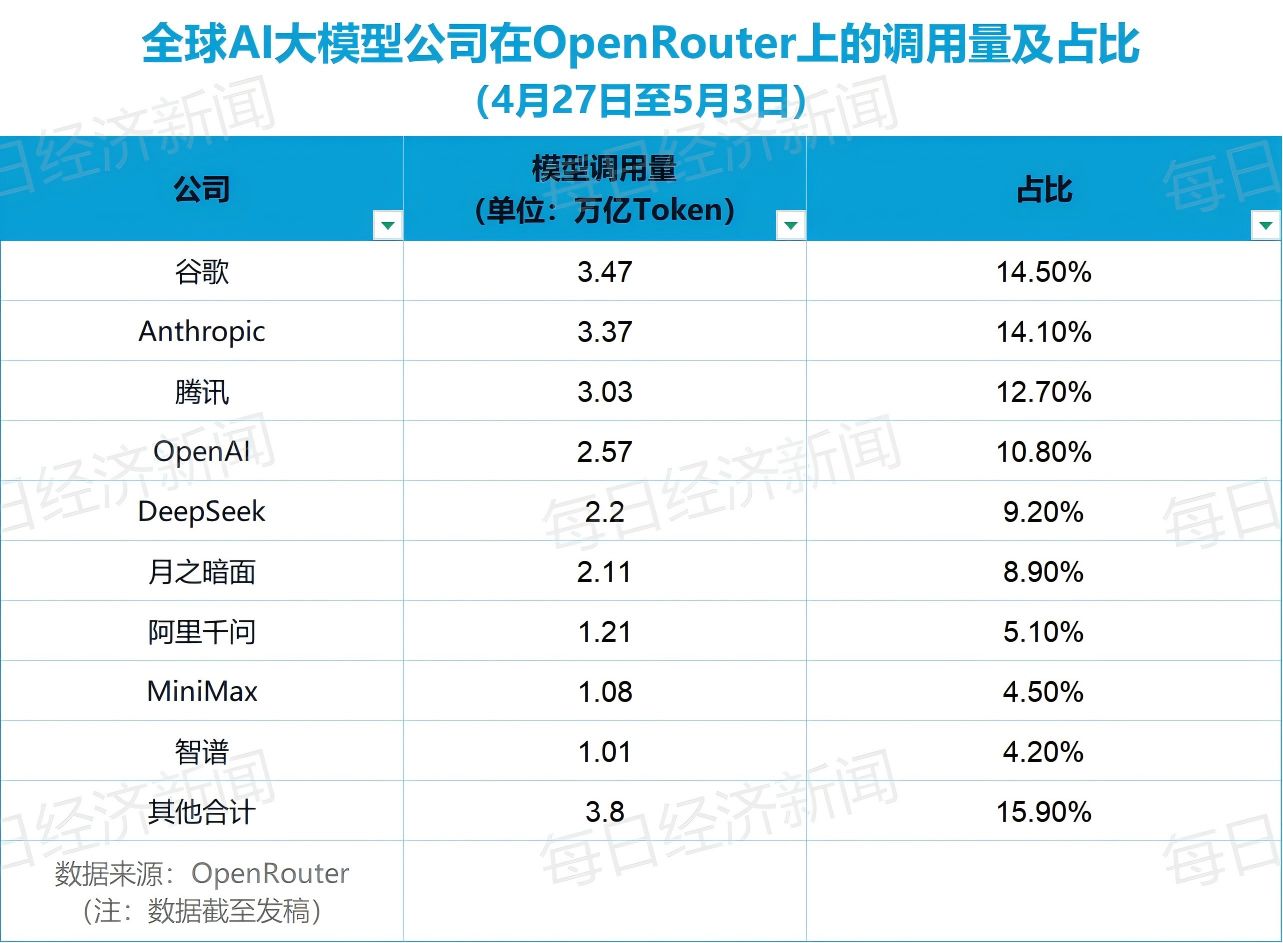
图片说明:DeepSeek用降价来占领市场份额的动机似乎并不强,数据来源于每日经济新闻
值得关注的是,根据《杭州日报》5月24日新闻,就在DeepSeek降价公告发布的同一天,有消息称,DeepSeek正在推进一轮高达700亿元人民币的融资,或将创下中国科技初创企业首轮融资纪录。创始人梁文锋向投资者明确表态:技术边界的拓展才是第一要务,而非急于变现。他个人还将出资约200亿元参与本轮融资。

图片说明:有关DeepSeek新一轮融资的传闻,数据来源于杭州网
因此,以DeepSeek的全球影响力以及创始人的相关表态来看,估值之家认为,DeepSeek本次降价,绝非出于价格战动机,而是软硬件一体生态初步构建成功后,基于技术复利支撑的“真降价”,AI行业的游戏规则正在发生着深刻地变化。
DeepSeek通过底层算法的改进,将GPU和显存的物理性能压榨到极限
尽管目的相同,都是为了大幅降低token成本,进而推动AI渗透率提升,但硅谷与DeepSeek走的完全是两条不同的路径:
硅谷降本的路径,由英伟达等一批硬件巨头引领,通过持续不断迭代出更先进的硬件,来降低token成本。
DeepSeek降本的路径,是通过极其精妙的数学工具应用,用算法和工程重构,通过技术复利积累,来压榨每一颗GPU与显存的物理极限。
简单来说,纵观DeepSeek从V1到V4的演进(每一个版本都有对应的技术论文,有兴趣的读者可在arxiv.org或huggingface.co上查询),独立开辟的重大创新算法不低于10种,包括但不限于:
V1中的算法创新:细粒度MoE混合专家架构,降低对GPU算力的占用。
V2中的算法创新:MLA多头潜在注意力网络,降低KV Cache对显存的占用。
V3中的算法创新:MTP多Token预测训练、ALFS无辅助损失的负载均衡、FP8混合精度训练等等,极致压榨训练效率与多Token预测。
V4中的算法创新:CSA与HCA混合压缩注意力、mHC流形约束超连接残差、Muon优化器与FP4 QAT等等,重构了注意力机制,1M长上下文推理FLOPs暴降至27%,KV Cache缩减至10%,极度契合Agentic AI场景。
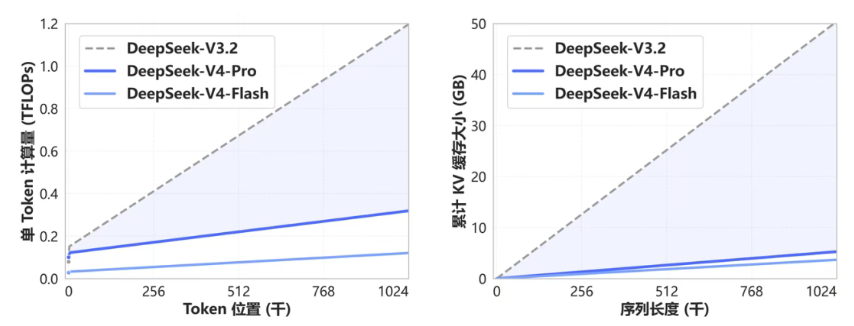
图片说明:DeepSeek-V4开创了一种全新的注意力机制,实现了全球领先的长上下文能力,数据来源于微信公众号
DeepSeek的斩杀线
B站博主“硅谷101”曾于4月29日发布视频《硅谷看DeepSeek V4》,其中被采访嘉宾、前OpenAI研究员Jenny Xiao,给出了一个非常有意思的判断:“DeepSeek最大的风险是,它为美国所有的AI大模型公司划定了一个“斩杀线”……DeepSeek就像在他们背后顶着一把枪。如果这些公司跑得不够快,DeepSeek就会追上来,那就会彻底摧毁他们的生意。”
图片说明:硅谷看DeepSeek V4,数据来源于哔哩哔哩
还好,DeepSeek-V4当前的能力还不足以“斩杀”最顶尖的Claude、GPT、Gemini大模型,可问题是,谁又能够回答,到底是DeepSeek在算法和软硬一体的技术复利增长更快呢,还是英伟达在硬件层面的技术复利增长更快呢?
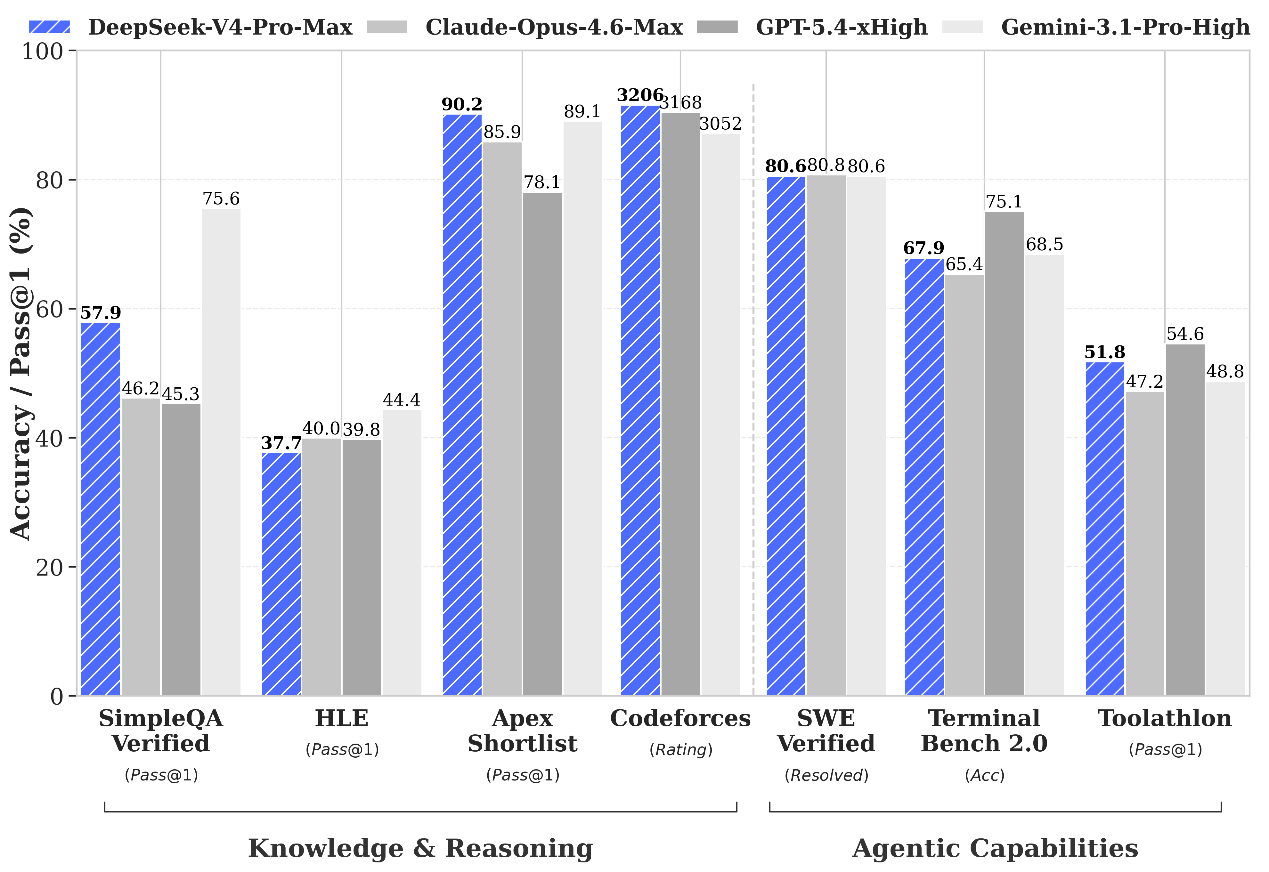
图片说明:DeepSeek-V4 Pro Max跑分,数据来源于微信公众号
因此结论是显而易见的,DeepSeek画出了一道清晰的斩杀线:即便优化到极致,其他大模型企业的成本,也很难比DeepSeek软硬一体化后的成本更低,因此其他大模型企业的AI能力必须要超过DeepSeek,否则将随时面临被斩杀的风险。
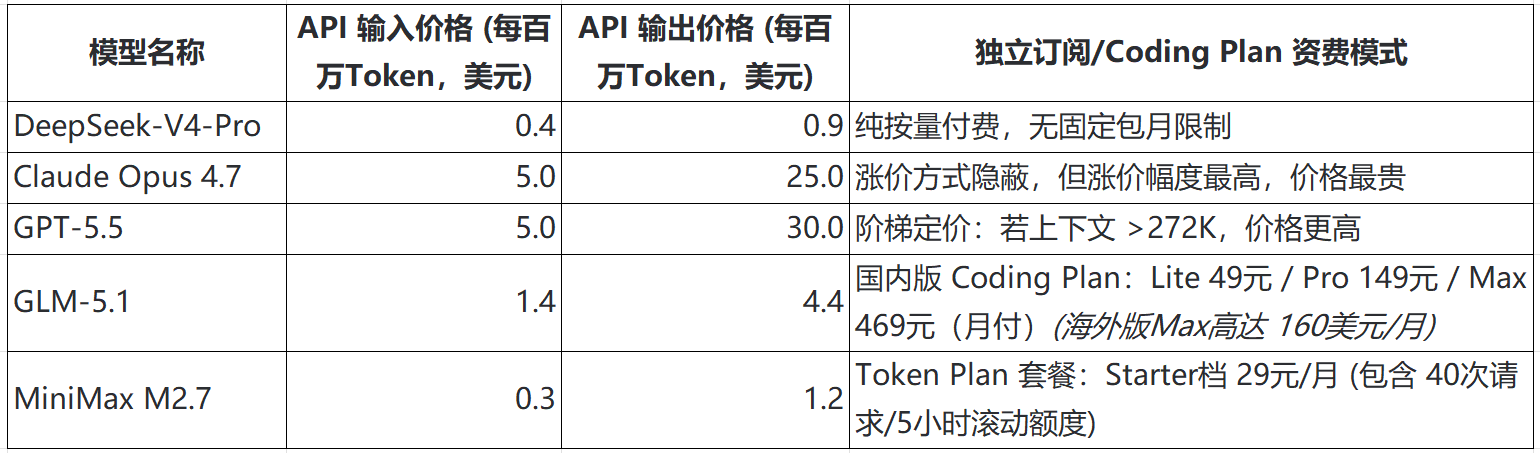
图片说明:大模型价格对比,按1:7汇率,数据来源于估值之家整理
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。

