预见MaaS2024:为大而大要刹车,以小驭大是上策


模型即服务(Model as a Service),简称MaaS,指的就是像OpenAI一样将自家AI模型的接口开放给广大企业用户或个人用户,用户仅仅需要在调用该模型的基础上,进行一定程度的个性化微调,就可以完成各种多元任务。说白了,只要是将模型应用起来,都可以视为模型即服务。
如今国内已有超过两百个所谓的大模型发布,国内“百模大战”如火如荼,大战下半场,舆论重心也逐渐从比较模型的参数规模和技术跑分,到思考将模型如何更好地应用到实处。
此时也出现了多种声音,关于大模型的应用,关于小模型的应用,基于大模型的小模型的应用等等。而小模型这一词汇逐渐占据视角的同时,也让不少人开始思考,那么多大模型是否真的有必要?以及大小模型将会如何共同发展?
01、为大而大,及时刹车
如今,模型的为大而大,正在刹车。
此前几个国内主要的大模型都曾宣称自己的参数规模超千亿级别,有的甚至是万亿,一时间,对比各大模型参数的数量级,成为不少AI爱好者茶余饭后的谈资。
然而百度李彦宏在近日的圆桌会议上发言称:“100多个大模型浪费社会资源……尤其在中国算力还受限制情况下,企业应该去探索各行各业的应用结合、全新的 App产品可能性等。”
李彦宏的发言并非是因为已经疲于作战,而是及时参透了为大而大的假象。
其实早在今年4月, OpenAI 首席执行官山姆·阿尔特曼(Sam Altman)就在麻省理工学院交流时说过:“我认为我们正处于巨型模型时代的结尾。”意在表示新的进步不会来自于让模型变得更大,“我们会以其他方式让他们变得更好。”
并且谷歌和微软也确实都在积极拥抱小模型。
谷歌在今年5月份的开发者大会上发布了新一代大语言模型 PaLM2,总共四个尺寸,其中参数体量最小的模型代号“壁虎”有被着重介绍,虽然当时并未给出“壁虎” 的具体参数规模,但谷歌CEO皮查伊说,“壁虎” 可以在手机上运行,而且速度足够快、不联网也能正常工作。
在11月的Ignite2023上,微软董事长兼首席执行官Nadella在主题演讲中就推出了基于微软云计算Azure的MaaS服务,紧接着便直言“微软喜欢小模型(SLM)”,并宣布了名为Phi-2的小型语言模型,该模型参数仅有27亿,尽管比起Phi-1.5的13亿参数有所增长,“但Phi-2在数学推理方面的性能提高了50%,并且是开源的,还将加入MaaS。”

这些国内外AI巨头大模型刹车的背后,实则是因为大模型竞赛问题丛生。
浪费算力的问题首当其冲。
11月中旬,微软研究院机器学习团队的负责人Sebastien Bubeck在推特上发布了一张图,显示了在MT bench的测评体系下,仅有27亿参数规模的Phi-2得分6.62,18000亿参数的GPT4得分8.99。
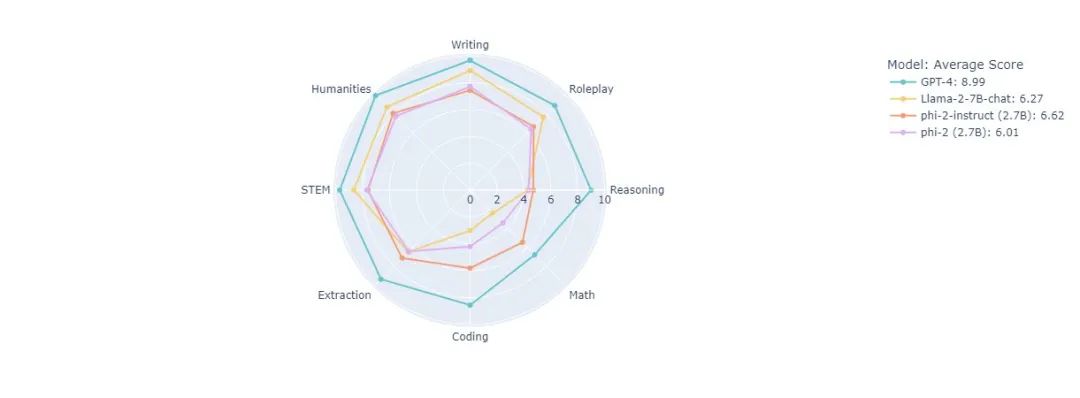
此前就有人爆料GPT4训练一次的费用可能达到6300万美元,然而如此高昂的代价,带来的并不是跟随成本线性增长的性能,山姆直言:“扩大模型规模的收益在递减。”
简而言之,办好七成的事情只需要花一块钱,与办好九成的事情可能需要一千元,对于每个企图入局大模型的企业而言,都是一件需要在战略层面值得抉择的事情。
显然,很多竭尽全力往更大规模上靠的大模型都选择了花更多的钱,还不一定能办好九成的事,造成了极大的算力浪费,这些算力都会实打实地消耗芯片和人力。
其次,更大模型带来的AI涌现,将变得愈发不可控制。
OpenAI认为,未来十年来将诞生超过人类的超级AI系统,彼时“基于人类反馈的强化学习技术将终结”。
也就是说,当AI超越人类后,AI不会再听人话来进行训练调整,那时候AI自我进化会带来什么后果,许多科幻作品已经为我们敲响警钟。
哪怕暂且不提不远不近的未来,只看眼前,通用大模型要应用到实处,本身就是一个难题。从技术出发去匹配应用场景,容易本末倒置。
此时许多垂直大模型才是用对了思路,直接从业务角度出发搭建大模型。
但关键在于,这些垂直大模型虽然在往更大规模上靠拢,却又算不上“大”。此时的“大模型”反而变成了一个象征意义的前后缀。
比如农业银行基于其本身业务推出的大模型小数(ChatABC),参数达百亿,相比起几个通用大模型动辄几千亿上万亿的参数规模,百亿并不算大。而面对垂直行业的业务,模型也实在没必要过大。
参数到达多少亿就算是大模型了,随着技术的发展,恐怕是不会有确切不变的标准的。微软现在认为自己27亿的模型就算小模型,但在早几年前普遍认为上亿就算大模型了。
不过不管多大多小,重点在于,搭建模型的目的是什么?
02、以小驭大,把缰绳交给用户
我们需要离用户更近的模型。
在用户层面来看,如何更快更好更低成本地使用工具达成自己的目的才是核心诉求。
如果将通用大模型直接给C端用户使用,使用成本高,不够个性化,恐怕都将成为难以维系商业可持续性的原因。
一个很典型的例子就是使用GPT4,每次对话结束后都会清空,它不会记住你之前有什么样的需求偏向,导致AI带来的效率提升大打折扣。相信也正因为如此,OpenAI会推出GPT的应用商店,允许用户搭建自己的GPT个性化应用。但GPT4仍要收取一定的会员费用,其实这笔费用对于世界各地广大C端用户而言并不算低。
那么这个时候,如果有一个直接从具体的业务场景出发训练搭建的模型,相信对于用户而言使用成本和效率都会更理想,而这样的模型往往也不会太大。
更不用说以后的模型即服务更大的应用场景在于让AI走下云端,走进移动端,将模型塞进手机、智能汽车、机器人等设备,进行离线运行,这只有较小的模型才能做到,上文说到的谷歌“壁虎”可在手机离线运行的意义便在于此,毕竟一个只要没网就无法运行的AI智能设备实在鸡肋。
在创业角度来看,搭建离用户更近的模型自然也更有生存空间。
一个很典型的例子就是,在SaaS(软件即服务)时代出现了一种情况:针对具体地区某个细分餐饮品类点单小程序这个场景,仅仅一家十人左右的公司就可以搭建起一套SaaS系统的研发和销售,创始人以前就是开这种餐饮店的,积累了相当多的同行资源以及场景痛点,如此的小系统,成本低,且更懂用户,在售卖软件环节轻而易举打败许多通用型餐饮点单SaaS系统。
MaaS时代极有可能也会出现这样的事情。
小一些的模型和大一些的模型当然不总是竞争关系,“大模型可以成为小模型的基座”这是很多人已经达成的共识,但在这个观点之下更底层的关系在于,较小的模型离用户更近,较大的模型走得更远,以小驭大,让人类走得更远。
在模型的应用开发方面,早就有用小模型驾驭大模型的实例。
比如上文提到的Ignite2023微软CEO就在介绍小模型时表示“可以将微软的云计算AzureAI能力从云扩展到任何端点”,调用GPT4的强大功能,定义自己的小模型。

国内则是有华为的盘古大模型3.0,提供5+N+X的三层解耦架构,其中的“5”指的就是基础大模型,“N”是通用层面,“X”则是具体应用场景的小模型。
较小的企业比如做营销解决方案服务的沃丰科技此前表示,他们在模型训练上采取了两种策略。一是固定一部分参数,只对其余参数进行迭代。二是在通用大模型基础上,进行小模型迭代。
个人用户基于GPT大模型搭建属于自己的GPT应用,也是典型的以小模型驾驭大模型,毕竟,小模型更懂你,大模型更全能。
而在AI进化这方面,上文提到过的OpenAI的隐忧,即AI的进化将变得不听人话,出现的问题也将超过人类认知,针对这个隐患,OpenAI目前想到的解决方案就是用小模型去监督大模型,原话是——“弱AI监督引导强AI”。
这来源于12月17日OpenAI在其官网上发布的一个全新研究成果:一个利用较弱的模型来引导更强模型的技术,即由弱到强的泛化。
在此前类似的研究中,由弱替代强被称为模型蒸馏。它可以生成一个小的、高效的模型,这个模型可以在资源受限的设备上运行,同时保持与大模型相似的性能。原本的研究出发点是在移动设备或边缘设备上部署较大的AI模型。
而OpenAI此举则是为了监督强AI的进化,OpenAI称其为超级对齐,我们可以理解为,让听得懂机器语言的大模型向小模型看齐,让既听得懂机器语言又听得懂自然语言的小模型向人类看齐。
OpenAI这里用的弱AI和强AI分别是GPT2和GPT4,GPT2的参数为15亿,如果研究结果切实可行,也就意味着人类可以用15亿参数的小模型驾驭18000亿参数的大模型。
由此可见,较小的模型不管从应用层面还是进化层面都成为了缰绳,缰绳的一边是人类,另一边是远超人类的超级AI。
好在国内早已经有以小驭大的土壤。
其实早在2021年就已经有微软联手英伟达推出5300亿参数的NLP(自然语言处理)模型,阿里达摩院当年也将预训练模型参数推高至十万亿,也已经有人注意到了上千亿参数的GPT3,但不管是GPT3还是其他,也许是彼时各大模型用了过大参数表现却差强人意,所以并没有被广泛关注。
到了2021年末,达摩院预测的2022年十大科技趋势报告中就有提到,在经历了一整年的参数竞赛模式之后,新的一年大模型的规模发展将进入冷静期,“人工智能研究将从大模型参数竞赛走向大小模型的协同进化,大模型向边、端的小模型输出模型能力,小模型负责实际的推理与执行;同时小模型再向大模型反馈算法与执行成效,让大模型的能力持续强化,形成有机循环的智能体系。”
旨在表示小模型对于大模型的应用和进化带来的协同作用。

2022年初有媒体报道,阿里巴巴达摩院、上海浙江大学高等研究院、上海人工智能实验室的联合研究团队,他们通过蒸馏压缩和参数共享等技术手段,将3.4亿参数的M6模型压缩到了百万参数,以大模型1/30的规模,保留了大模型90%以上的性能。
尽管相比起现在,3.4亿规模的参数并不算大,但这却为大模型的瘦身,以及以小驭大开了一个好头。
据当时的媒体报道,该技术有被应用到支付宝搜索框。
接着,就在不远的将来2022年末,GPT3.5横空出世,保持了GPT3的参数规模,表现结果却足以惊艳全世界。之后来到2023年,上千亿参数规模的模型之战便再次触发。
如果从这条时间线捋下来,2023年初开始的这场模型竞赛反而不应该聚焦在“大”上,而是应该在“大而好”。
而如今大模型进入应用阶段,核心也将是在更大规模上的以小驭大。
03、写在最后
著名科幻动画片《爱,死亡和机器人》第二季第一集《自动化客户服务》中讲述的故事是,人们生活在一个几乎所有的设备都连接了智能AI的未来世界,在故事前半部分的烘托中,人类跟这些AI设备完全没有深度交流,仅仅只是下达指令让他们做事。故事的结局是,所有设备联合起来追杀人类。
同样也是《爱,死亡和机器人》,第一季让人映像深刻的《齐马蓝》,讲述的则是一个叫做齐马的艺术家,他边画画边探索宇宙的奥秘。然而他的每一幅作品中间都有一个蓝色的方块。
后来齐马接收采访,讲述了一个泳池清洗机的故事,并称这个泳池清洗机“最初来源于一位才华横溢的年轻女士的创造”,“她最喜欢的机器人就是这个。”后来,这位女士基于这个小机器人不断地进行改造,直到这位女士死后,机器人被继承给了别人继续迭代,并变得越来越像齐马。
在最后一场艺术家的发布会上,齐马跳进泳池里欣然切断了自己的高级大脑,只剩下他最本真的部分——泳池清洗机,然后开始用自己的小刷子刷泳池上的蓝色瓷砖块,并发出感慨——
“我对真理的探索终于结束了,我回家了。”
*题图及文中配图来源于网络。
财经号声明: 本文由入驻中金在线财经号平台的作者撰写,观点仅代表作者本人,不代表中金在线立场。仅供读者参考,并不构成投资建议。投资者据此操作,风险自担。同时提醒网友提高风险意识,请勿私下汇款给自媒体作者,避免造成金钱损失,风险自负。如有文章和图片作品版权及其他问题,请联系本站。

